Binary Image Classification
1. Exploring the dataset
- Dataset: Histopathologic Cancer Detection competition on Kaggle.
- Goal: Classifying image patches as normal or malignant.
Read train_labels.csv and explore
import pandas as pd
path2csv = './data/histopathologic-cancer-detection/train_labels.csv'
labels_df = pd.read_csv(path2csv)
labels_df.head()
| id | label | |
|---|---|---|
| 0 | f38a6374c348f90b587e046aac6079959adf3835 | 0 |
| 1 | c18f2d887b7ae4f6742ee445113fa1aef383ed77 | 1 |
| 2 | 755db6279dae599ebb4d39a9123cce439965282d | 0 |
| 3 | bc3f0c64fb968ff4a8bd33af6971ecae77c75e08 | 0 |
| 4 | 068aba587a4950175d04c680d38943fd488d6a9d | 0 |
# count the number of normal and malignant cases
labels_df['label'].value_counts()
0 130908
1 89117
Name: label, dtype: int64
# retina option
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('retina')
# look at a histogram of the labels
labels_df['label'].hist()
<AxesSubplot:>

Visualize a few images that have a positive label
positive: at least one pixel of tumor tissue
import matplotlib.pylab as plt
from PIL import Image, ImageDraw
import numpy as np
import os
# get ids for malignant images
malignantIds = labels_df.loc[labels_df['label'] == 1]['id'].values
print(len(malignantIds))
malignantIds
89117
array(['c18f2d887b7ae4f6742ee445113fa1aef383ed77',
'a24ce148f6ffa7ef8eefb4efb12ebffe8dd700da',
'7f6ccae485af121e0b6ee733022e226ee6b0c65f', ...,
'309210db7f424edbc22b2d13bf2fa27518b18f5c',
'd4b854fe38b07fe2831ad73892b3cec877689576',
'a81f84895ddcd522302ddf34be02eb1b3e5af1cb'], dtype=object)
# data is stored here
path2train = './data/histopathologic-cancer-detection/train/'
Define a flag to show images in grayscale or color mode
# show images in grayscale, if you want color change it to True
color = False
Set figure sizes
plt.rcParams['figure.figsize'] = (10.0, 10.0)
plt.subplots_adjust(wspace=0, hspace=0)
nrows, ncols = 3, 3
<Figure size 720x720 with 0 Axes>
Display the images
PIL.ImageDraw.Draw(im, mode=None)
Creates an object that can be used to draw in the given image. Note that the image will be modified in place.
ImageDraw.rectangle(xy, fill=None, outline=None, width=1)
Draws a rectangle.
- xy: Two points to define the bounding box. Sequence of either [(x0, y0), (x1, y1)] or [x0, y0, x1, y1]. The second point is just outside the drawn rectangle.
- outline: Color to use for the outline.
- fill: Color to use for the fill.
- width: The line width, in pixels.
for i, id_ in enumerate(malignantIds[:nrows * ncols]):
full_filenames = os.path.join(path2train, id_ + '.tif')
# load image
img = Image.open(full_filenames)
# draw a 32 * 32 rectangle
draw = ImageDraw.Draw(img)
draw.rectangle(((32, 32), (64, 64)), outline='green')
plt.subplot(nrows, ncols, i + 1)
if color is True:
plt.imshow(np.array(img))
else:
plt.imshow(np.array(img)[:,:,0], cmap='gray')
plt.axis('off')

Image’s shape and minimum/maximum pixel values
print('image shape:', np.array(img).shape)
print('pixel values range from %s to %s' %(np.min(img), np.max(img)))
image shape: (96, 96, 3)
pixel values range from 0 to 255
2. Creating a custom dataset
Dataset (class): a powerful tool to handle large datasets in PyTorch
__len__: returns the dataset’s length.__getitem__: returns an image at the specified index.
Define a class for the custom dataset
# load the required packages
from PIL import Image
import torch
from torch.utils.data import Dataset
import pandas as pd
import torchvision.transforms as transforms
import os
import time
# fix torch random seed
torch.manual_seed(0)
<torch._C.Generator at 0x7fb741048d98>
help(Dataset)
Help on class Dataset in module torch.utils.data.dataset:
class Dataset(typing.Generic)
| An abstract class representing a :class:`Dataset`.
|
| All datasets that represent a map from keys to data samples should subclass
| it. All subclasses should overwrite :meth:`__getitem__`, supporting fetching a
| data sample for a given key. Subclasses could also optionally overwrite
| :meth:`__len__`, which is expected to return the size of the dataset by many
| :class:`~torch.utils.data.Sampler` implementations and the default options
| of :class:`~torch.utils.data.DataLoader`.
|
| .. note::
| :class:`~torch.utils.data.DataLoader` by default constructs a index
| sampler that yields integral indices. To make it work with a map-style
| dataset with non-integral indices/keys, a custom sampler must be provided.
|
| Method resolution order:
| Dataset
| typing.Generic
| builtins.object
|
| Methods defined here:
|
| __add__(self, other:'Dataset[T_co]') -> 'ConcatDataset[T_co]'
|
| __getitem__(self, index) -> +T_co
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __abstractmethods__ = frozenset()
|
| __args__ = None
|
| __extra__ = None
|
| __next_in_mro__ = <class 'object'>
| The most base type
|
| __orig_bases__ = (typing.Generic[+T_co],)
|
| __origin__ = None
|
| __parameters__ = (+T_co,)
|
| __tree_hash__ = -9223363260025027557
|
| ----------------------------------------------------------------------
| Static methods inherited from typing.Generic:
|
| __new__(cls, *args, **kwds)
| Create and return a new object. See help(type) for accurate signature.
# define the histoCancerDataset class
class histoCancerDataset(Dataset):
def __init__(self, data_dir, transform, data_type='train'):
# path to images
path2data = os.path.join(data_dir, data_type)
# get a list of images
filenames = os.listdir(path2data)
# get the full path to images
self.full_filenames = [os.path.join(path2data, f) for f in filenames]
# labels are in a csv file named train_labels.csv
csv_filename = data_type + '_labels.csv'
path2csvLabels = os.path.join(data_dir, csv_filename)
labels_df = pd.read_csv(path2csvLabels)
# set data frame index to id
labels_df.set_index('id', inplace=True)
# obtain labels form data frame
self.labels = [labels_df.loc[filename[:-4]].values[0] for filename in filenames]
self.transform = transform
def __len__(self):
# return size of dataset
return len(self.full_filenames)
def __getitem__(self, idx):
# open image, apply transforms and return with label
image = Image.open(self.full_filenames[idx]) # PIL image
image = self.transform(image)
return image, self.labels[idx]
Define the transformation function
import torchvision.transforms as transforms
# simple transformation that only converts a PIL image into Pytorch tensors.
data_transformer = transforms.Compose([transforms.ToTensor()])
Define an object of the custom dataset for the train folder
data_dir = './data/histopathologic-cancer-detection/'
histo_dataset = histoCancerDataset(data_dir, data_transformer, 'train')
print(len(histo_dataset))
220025
Load an image using the custom dataset
# load an image
img, label = histo_dataset[9]
print(img.shape, torch.min(img), torch.max(img))
torch.Size([3, 96, 96]) tensor(0.0549) tensor(1.)
3. Splitting the dataset
For tracking the model’s performance during training, we need to provide a validation dataset
- 20% of histo_dataset as the validation dataset
from torch.utils.data import random_split
# split histo_dataset
len_histo = len(histo_dataset)
len_train = int(0.8 * len_histo)
len_val = len_histo - len_train
torch.utils.data.random_split(dataset, lengths, generator=<torch._C.Generator object>)
Randomly split a dataset into non-overlapping new datasets of given lengths.
Optionally fix the generator for reproducible results
- dataset(Dataset): Dataset to be split
- lengths(sequence): lengths of splits to be produced
- generator(Generator): Generator used for the random permutation.
train_ds, val_ds = random_split(histo_dataset, [len_train, len_val])
print('train dataset length:', len(train_ds))
print('validation dataset length:', len(val_ds))
train dataset length: 176020
validation dataset length: 44005
# get an image from the training dataset
for x, y in train_ds:
print(x.shape, y)
break
torch.Size([3, 96, 96]) 0
# get an image from the validation dataset
for x, y in val_ds:
print(x.shape, y)
break
torch.Size([3, 96, 96]) 1
Display a few samples
from torchvision import utils
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
Define a helper function to show an image
def show(img, y, color=False):
# convert tensor to numpy array
npimg = img.numpy()
# convert to H * W * C shape
npimg_tr = np.transpose(npimg, (1, 2, 0))
if color == False:
npimg_tr = npimg_tr[:, :, 0]
plt.imshow(npimg_tr, interpolation='nearest', cmap='gray')
else:
# display images
plt.imshow(npimg_tr, interpolation='nearest')
plt.title('label: ' + str(y))
Create a grid of sample images
torchvision.utils.make_grid(tensor: Union[torch.Tensor, List[torch.Tensor]], nrow: int = 8, padding: int = 2, normalize: bool = False, value_range: Optional[Tuple[int, int]] = None, scale_each: bool = False, pad_value: int = 0, **kwargs) → torch.Tensor
Make a grid of images.
- tensor (Tensor or list) – 4D mini-batch Tensor of shape (B x C x H x W) or a list of images all of the same size.
- nrow (int, optional) – Number of images displayed in each row of the grid. The final grid size is (B / nrow, nrow). Default: 8.
- padding (int, optional) – amount of padding. Default: 2.
- normalize (bool, optional) – If True, shift the image to the range (0, 1), by the min and max values specified by range. Default: False.
- value_range (tuple, optional) – tuple (min, max) where min and max are numbers, then these numbers are used to normalize the image. By default, min and max are computed from the tensor.
- scale_each (bool, optional) – If True, scale each image in the batch of images separately rather than the (min, max) over all images. Default: False.
- pad_value (float, optional) – Value for the padded pixels. Default: 0.
grid_size = 4
rnd_inds = np.random.randint(0, len(train_ds), grid_size)
print('image indices:', rnd_inds)
x_grid_train = [train_ds[i][0] for i in rnd_inds]
y_grid_train = [train_ds[i][1] for i in rnd_inds]
x_grid_train = utils.make_grid(x_grid_train, nrow=4, padding=2)
print(x_grid_train.shape)
plt.rcParams['figure.figsize'] = (10.0, 5)
show(x_grid_train, y_grid_train)
image indices: [ 43567 173685 117952 152315]
torch.Size([3, 100, 394])
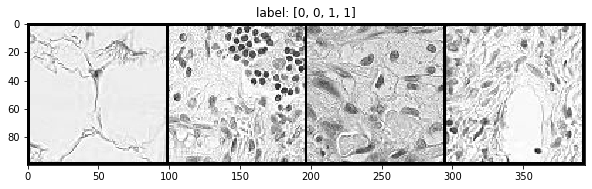
show a few samples from val_ds
grid_size = 4
rnd_inds = np.random.randint(0, len(val_ds), grid_size)
print('image indices:', rnd_inds)
x_grid_val = [val_ds[i][0] for i in range(grid_size)]
y_grid_val = [val_ds[i][1] for i in range(grid_size)]
x_grid_val = utils.make_grid(x_grid_val, nrow=4, padding=2)
print(x_grid_val.shape)
show(x_grid_val, y_grid_val)
image indices: [30403 32103 41993 20757]
torch.Size([3, 100, 394])
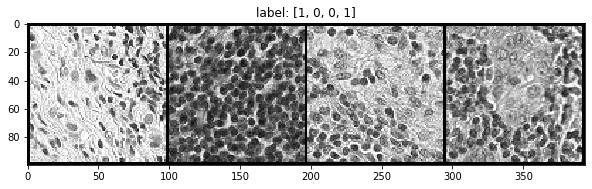
4. Transforming the data
Image transformation: expanding the dataset or resizing and normalizing it to achieve better model performance.
- horizontal and vertical flipping
- rotation
- resizing
torchvision package has the on-the-fly image transformation method
Define a few image transformations
torchvision.transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=<InterpolationMode.BILINEAR: 'bilinear'>)
Crop a random portion of image and resize it to a given size.
If the image is torch Tensor, it is expected to have […, H, W] shape, where … means an arbitrary number of leading dimensions.
A crop of the original image is made: the crop has a random area (H * W) and a random aspect ratio.
This crop is finally resized to the given size. This is popularly used to train the Inception networks.
- size(int or sequence): expected output size of the crop, for each edge.
- If size is an int instead of sequence like (h, w), a square output size (size, size) is made.
- If provided a sequence of length 1, it will be interpreted as (size[0], size[0]).
- scale(tuple of python:float): Specifies the lower and upper bounds for the random area of the crop, before resizing.
- The scale is defined with respect to the area of the original image.
- ratio(tuple of python:float): lower and upper bounds for the random aspect ratio of the crop, before resizing.
- interpolation(InterpolationMode): Desired interpolation enum defined by
torchvision.transforms.InterpolationMode.- Default is
InterpolationMode.BILINEAR. - If input is Tensor, only
InterpolationMode.NEAREST,InterpolationMode.BILINEARandInterpolationMode.BICUBICare supported. - For backward compatibility integer values (e.g.
PIL.Image.NEAREST) are still acceptable.
- Default is
# define the transformations for the training dataset
train_transformer = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.RandomRotation(45),
transforms.RandomResizedCrop(96, scale=(0.8, 1.0), ratio=(1.0, 1.0)),
transforms.ToTensor()
])
train_transformer
Compose(
RandomHorizontalFlip(p=0.5)
RandomVerticalFlip(p=0.5)
RandomRotation(degrees=[-45.0, 45.0], resample=False, expand=False)
RandomResizedCrop(size=(96, 96), scale=(0.8, 1.0), ratio=(1.0, 1.0), interpolation=PIL.Image.BILINEAR)
ToTensor()
)
# valdiation dataset -> don't need any augmentation, only convert the images into tensors
val_transformer = transforms.Compose([transforms.ToTensor()])
Overwrite the transform functions of train_ds and val_ds
# overwrite the transform functions
train_ds.transform = train_transformer
val_ds.transform = val_transformer
5. Creating dataloaders
If we do not use dataloaders, we have to write code to loop over datasets and extract a data batch
- Using PyTorch Dataloader, this process can be made automatically
from torch.utils.data import DataLoader
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False)
Data loader. Combines a dataset and a sampler, and provides an iterable over the given dataset.
The DataLoader supports both map-style and iterable-style datasets with single- or multi-process loading, customizing loading order and optional automatic batching (collation) and memory pinning.
- dataset (Dataset) – dataset from which to load the data.
- batch_size (int, optional) – how many samples per batch to load (default: 1).
- shuffle (bool, optional) – set to True to have the data reshuffled at every epoch (default: False).
- sampler (Sampler or Iterable, optional) – defines the strategy to draw samples from the dataset. Can be any Iterable with
__len__implemented. If specified, shuffle must not be specified. - batch_sampler (Sampler or Iterable, optional) – like sampler, but returns a batch of indices at a time. Mutually exclusive with batch_size, shuffle, sampler, and drop_last.
- num_workers (int, optional) – how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0)
- collate_fn (callable, optional) – merges a list of samples to form a mini-batch of Tensor(s). Used when using batched loading from a map-style dataset.
- pin_memory (bool, optional) – If True, the data loader will copy Tensors into CUDA pinned memory before returning them. If your data elements are a custom type, or your collate_fn returns a batch that is a custom type, see the example below.
- drop_last (bool, optional) – set to True to drop the last incomplete batch, if the dataset size is not divisible by the batch size. If False and the size of dataset is not divisible by the batch size, then the last batch will be smaller. (default: False)
- timeout (numeric, optional) – if positive, the timeout value for collecting a batch from workers. Should always be non-negative. (default: 0)
- worker_init_fn (callable, optional) – If not None, this will be called on each worker subprocess with the worker id (an int in [0, num_workers - 1]) as input, after seeding and before data loading. (default: None)
- generator (torch.Generator, optional) – If not None, this RNG will be used by RandomSampler to generate random indexes and multiprocessing to generate base_seed for workers. (default: None)
- prefetch_factor (int, optional, keyword-only arg) – Number of samples loaded in advance by each worker. 2 means there will be a total of 2 * num_workers samples prefetched across all workers. (default: 2)
- persistent_workers (bool, optional) – If True, the data loader will not shutdown the worker processes after a dataset has been consumed once. This allows to maintain the workers Dataset instances alive. (default: False)
define two dataloaders for the datasets
train_dl = DataLoader(train_ds, batch_size=32, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=64, shuffle=False)
# extract a batch from training data
for x, y in train_dl:
print(x.shape)
print(y.shape)
break
torch.Size([32, 3, 96, 96])
torch.Size([32])
# extract a batch from validation data
for x, y in val_dl:
print(x.shape)
print(y.shape)
break
torch.Size([64, 3, 96, 96])
torch.Size([64])
6. Building the classification model
model: four CNNs(Convolutional Neural Networks) and two FCLs(Fully Connected Layers)
- after each convolutional layer, there is a pooling layer
- output layer is for the binary classification
create dumb baselines for the validation dataset
# get labels for validation dataset
y_val = [y for _, y in val_ds]
# define a function to calculate the classification accuracy
def accuracy(labels, out):
return np.sum(out==labels) / float(len(labels))
numpy.zeros_like(a, dtype=None, order='K', subok=True, shape=None)
Return an array of zeros with the same shape and type as a given array.
- a(array_like): The shape and data-type of a define these same attributes of the returned array.
- dtype(data-type, optional): Overrides the data type of the result.
- order({‘C’, ‘F’, ‘A’, or ‘K’}, optional): Overrides the memory layout of the result. ‘C’ means C-order, ‘F’ means F-order, ‘A’ means ‘F’ if a is Fortran contiguous, ‘C’ otherwise. ‘K’ means match the layout of a as closely as possible.
- subok(bool, optional): If True, then the newly created array will use the sub-class type of a, otherwise it will be a base-class array. Defaults to True.
- shape(int or sequence of ints, optional): Overrides the shape of the result. If order=’K’ and the number of dimensions is unchanged, will try to keep order, otherwise, order=’C’ is implied.
# accuracy all zero predictions
acc_all_zeros = accuracy(y_val, np.zeros_like(y_val))
print("accuracy all zero prediction: %.2f" %acc_all_zeros)
accuracy all zero prediction: 0.59
# accuracy all ones predictions
acc_all_ones = accuracy(y_val, np.ones_like(y_val))
print("accuracy all one prediction: %.2f" %acc_all_ones)
accuracy all one prediction: 0.41
# accuracy random predictions
acc_random = accuracy(y_val, np.random.randint(2, size=len(y_val)))
print("accuracy random prediction: %.2f" %acc_random)
accuracy random prediction: 0.50
implement a helper function to calculate the output size of a CNN layer
import torch.nn as nn
# define the helper function
def findConv2dOutShape(H_in, W_in, conv, pool=2):
# get conv arguments
kernel_size = conv.kernel_size
stride = conv.stride
padding = conv.padding
dilation = conv.dilation
# Ref: https://pytorch.org/docs/stable/nn.html
H_out = np.floor((H_in + 2 * padding[0] - dilation[0] * (kernel_size[0] - 1) - 1) / stride[0] + 1)
W_out = np.floor((W_in + 2 * padding[1] - dilation[1] * (kernel_size[1] - 1) - 1) / stride[1] + 1)
if pool:
H_out /= pool
W_out /= pool
return int(H_out), int(W_out)
# example
conv1 = nn.Conv2d(3, 8, kernel_size=3)
h, w = findConv2dOutShape(96, 96, conv1)
print(h, w)
47 47
implement the CNN model
# import required packages
import torch.nn as nn
import torch.nn.functional as F
# define the Net class
class Net(nn.Module):
def __init__(self, params):
super(Net, self).__init__()
C_in, H_in, W_in = params['input_shape']
init_f = params['initial_filters']
num_fc1 = params['num_fc1']
num_classes = params['num_classes']
self.dropout_rate = params['dropout_rate']
self.conv1 = nn.Conv2d(C_in, init_f, kernel_size=3)
h, w = findConv2dOutShape(H_in, W_in, self.conv1)
self.conv2 = nn.Conv2d(init_f, 2 * init_f, kernel_size=3)
h, w = findConv2dOutShape(h, w, self.conv2)
self.conv3 = nn.Conv2d(2 * init_f, 4 * init_f, kernel_size=3)
h, w = findConv2dOutShape(h, w, self.conv3)
self.conv4 = nn.Conv2d(4 * init_f, 8 * init_f, kernel_size=3)
h, w = findConv2dOutShape(h, w, self.conv4)
# compute the flatten size
self.num_flatten = h * w * 8 * init_f
self.fc1 = nn.Linear(self.num_flatten, num_fc1)
self.fc2 = nn.Linear(num_fc1, num_classes)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv3(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv4(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, self.num_flatten)
x = F.relu(self.fc1(x))
x = F.dropout(x, self.dropout_rate, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
construct an object of the Net class
# dict to define model parameters
params_model = {
'input_shape': (3, 96, 96),
'initial_filters': 8,
'num_fc1': 100,
'dropout_rate': 0.25,
'num_classes': 2,
}
# create model
cnn_model = Net(params_model)
move the model to a cuda device if one’s available
# move model to cuda/gpu device
if torch.cuda.is_available():
device = torch.device('cuda')
cnn_model = cnn_model.to(device)
model check
cnn_model
Net(
(conv1): Conv2d(3, 8, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(8, 16, kernel_size=(3, 3), stride=(1, 1))
(conv3): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1))
(conv4): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=1024, out_features=100, bias=True)
(fc2): Linear(in_features=100, out_features=2, bias=True)
)
verify the model device
next(cnn_model.parameters()).device
device(type='cpu')
get a summary of the model
from torchsummary import summary
summary(cnn_model, input_size=(3, 96, 96), device=torch.device('cpu').type)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 8, 94, 94] 224
Conv2d-2 [-1, 16, 45, 45] 1,168
Conv2d-3 [-1, 32, 20, 20] 4,640
Conv2d-4 [-1, 64, 8, 8] 18,496
Linear-5 [-1, 100] 102,500
Linear-6 [-1, 2] 202
================================================================
Total params: 127,230
Trainable params: 127,230
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.11
Forward/backward pass size (MB): 0.92
Params size (MB): 0.49
Estimated Total Size (MB): 1.51
----------------------------------------------------------------
7. Defining th loss function
standard loss function for classification tasks
- cross-entropy loss
- logloss
output activation / number of outputs / loss function
None / 1 / nn.BCEWithLogitsLoss
Sigmoid / 1 / nn.BCELoss
None / 2 / nn.CrossEntropyLoss
log_softmax / 2 / nn.NLLLoss
log_softmax function: easier to expand to multi-class classification
- PyTorch combines the log and softmax operations into one function due to numerical stability and speed
define the loss function
# nn.NLLLoss(): negative log-likelihood loss
loss_func = nn.NLLLoss(reduction='sum')
use the loss in an example
# fix random seed
torch.manual_seed(9)
<torch._C.Generator at 0x7fb83a9b2de0>
n, c = 8, 2
y = torch.randn(n, c, requires_grad=True)
ls_F = nn.LogSoftmax(dim=1)
y_out = ls_F(y)
y
tensor([[-1.0674, -0.7172],
[ 1.0897, -1.5747],
[ 1.4460, 0.6191],
[-0.7737, -2.4656],
[ 0.9968, 0.4524],
[-0.3464, -0.7245],
[ 1.7059, 2.2282],
[-0.0677, 0.2331]], requires_grad=True)
y_out
tensor([[-0.8835, -0.5333],
[-0.0673, -2.7317],
[-0.3628, -1.1897],
[-0.1690, -1.8609],
[-0.4576, -1.0019],
[-0.5218, -0.9000],
[-0.9880, -0.4657],
[-0.8548, -0.5540]], grad_fn=<LogSoftmaxBackward>)
y_out.shape
torch.Size([8, 2])
target = torch.randint(c, size=(n,))
target
tensor([0, 1, 1, 1, 1, 0, 0, 0])
target.shape
torch.Size([8])
loss = loss_func(y_out, target)
loss.item()
10.032448768615723
compute the gradients of the loss with respect to y
loss.backward()
y.data
tensor([[-1.0674, -0.7172],
[ 1.0897, -1.5747],
[ 1.4460, 0.6191],
[-0.7737, -2.4656],
[ 0.9968, 0.4524],
[-0.3464, -0.7245],
[ 1.7059, 2.2282],
[-0.0677, 0.2331]])
8. Defining the optimizer
torch.optim packages provides the implementation of common optimizers
- optimizer: holds the current state and updates the parameters based on the computed gradients
- binary classification tasks - SGD, Adam
- learning schedules: tools for automatically adjusting the learning rate during training to improve model performance
define an object of the Adam optimizer with a learning rate of 3e-4
from torch import optim
opt = optim.Adam(cnn_model.parameters(), lr=3e-4)
opt
Adam (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
eps: 1e-08
lr: 0.0003
weight_decay: 0
)
read the current value of the learning rate
# get learning rate
def get_lr(opt):
for param_group in opt.param_groups:
return param_group['lr']
current_lr = get_lr(opt)
print('current lr={}'.format(current_lr))
current lr=0.0003
define a learning scheduler using the ReduceLROnPlateau method
from torch.optim.lr_scheduler import ReduceLROnPlateau
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08, verbose=False)
Reduce learning rate when a metric has stopped improving. Models often benefit from reducing the learning rate by a factor of 2-10 once learning stagnates. This scheduler reads a metrics quantity and if no improvement is seen for a ‘patience’ number of epochs, the learning rate is reduced.
- optimizer (Optimizer) – Wrapped optimizer.
- mode (str) – One of min, max. In min mode, lr will be reduced when the quantity monitored has stopped decreasing; in max mode it will be reduced when the quantity monitored has stopped increasing. Default: ‘min’.
- factor (float) – Factor by which the learning rate will be reduced. new_lr = lr * factor. Default: 0.1.
- patience (int) – Number of epochs with no improvement after which learning rate will be reduced. For example, if patience = 2, then we will ignore the first 2 epochs with no improvement, and will only decrease the LR after the 3rd epoch if the loss still hasn’t improved then. Default: 10.
- threshold (float) – Threshold for measuring the new optimum, to only focus on significant changes. Default: 1e-4.
- threshold_mode (str) – One of rel, abs. In rel mode, dynamic_threshold = best * ( 1 + threshold ) in ‘max’ mode or best * ( 1 - threshold ) in min mode. In abs mode, dynamic_threshold = best + threshold in max mode or best - threshold in min mode. Default: ‘rel’.
- cooldown (int) – Number of epochs to wait before resuming normal operation after lr has been reduced. Default: 0.
- min_lr (float or list) – A scalar or a list of scalars. A lower bound on the learning rate of all param groups or each group respectively. Default: 0.
- eps (float) – Minimal decay applied to lr. If the difference between new and old lr is smaller than eps, the update is ignored. Default: 1e-8.
- verbose (bool) – If True, prints a message to stdout for each update. Default: False.
# define learning rate scheduler
lr_scheduler = ReduceLROnPlateau(opt, mode='min', factor=0.5, patience=20, verbose=1)
learn how the learning rate schedule works
for i in range(100):
lr_scheduler.step(1)
Epoch 22: reducing learning rate of group 0 to 1.5000e-04.
Epoch 43: reducing learning rate of group 0 to 7.5000e-05.
Epoch 64: reducing learning rate of group 0 to 3.7500e-05.
Epoch 85: reducing learning rate of group 0 to 1.8750e-05.
9. Training and evaluation of the model
build a few helper functions for better code readability and to avoid code repetition
develop a helper function to count the number of correct predictions per data batch
torch.eq(input, other, *, out=None) → Tensor
Computes element-wise equality
The second argument can be a number or a tensor whose shape is broadcastable with the first argument.
- input (Tensor) – the tensor to compare
- other (Tensor or float) – the tensor or value to compare
def metrics_batch(output, target):
# get output class
pred = output.argmax(dim=1, keepdim=True)
# compare output class with target class
corrects = pred.eq(target.view_as(pred)).sum().item()
return corrects
develop a helper function to compute the loss value per batch of data
def loss_batch(loss_func, output, target, opt=None):
loss = loss_func(output, target)
with torch.no_grad():
metric_b = metrics_batch(output, target)
if opt is not None:
opt.zero_grad()
loss.backward()
opt.step()
return loss.item(), metric_b
develop a helper function to compute the loss value and the performance metric for the entire dataset, also called an epoch
# define the loss_epoch function
def loss_epoch(model, loss_func, dataset_dl, sanity_check=False, opt=None):
running_loss = 0.0
running_metric = 0.0
len_data = len(dataset_dl.dataset)
# internal loop over the dataset
for xb, yb in dataset_dl:
# move batch to device
# xb = xb.to(device)
# yb = yb.to(device)
# get model output
output = model(xb)
# get loss per batch
loss_b, metric_b = loss_batch(loss_func, output, yb, opt)
# update running loss
running_loss += loss_b
# update running metric
if metric_b is not None:
running_metric += metric_b
# break the loop in case of sanity check
if sanity_check is True:
break
# average loss value
loss = running_loss / float(len_data)
# average metric value
metric = running_metric / float(len_data)
return loss, metric
develop the train_val function
def train_val(model, params):
# extract model parameters
num_epochs = params['num_epochs']
loss_func = params['loss_func']
opt = params['optimizer']
train_dl = params['train_dl']
val_dl = params['val_dl']
sanity_check = params['sanity_check']
lr_scheduler = params['lr_scheduler']
path2weights = params['path2weights']
# history of loss values in each epoch
loss_history = {
'train': [],
'val': [],
}
# history of metric values in each epoch
metric_history = {
'train': [],
'val': [],
}
# a deep copy of weights for the best performing model
best_model_wts = copy.deepcopy(model.state_dict())
# initialize best loss to a large value
best_loss = float('inf')
# define a loop that calculates the training loss over an epoch
# main loop
for epoch in range(num_epochs):
# get current learning rate
current_lr = get_lr(opt)
print('Epoch {}/{}, current lr={}'.format(epoch, num_epochs - 1, current_lr))
# train model on training dataset
model.train()
train_loss, train_metric = loss_epoch(model, loss_func, train_dl, sanity_check, opt)
# collect loss and metric for training dataset
loss_history['train'].append(train_loss)
metric_history['train'].append(train_metric)
# evaluate model on validation dataset
model.eval()
with torch.no_grad():
val_loss, val_metric = loss_epoch(model, loss_func, val_dl, sanity_check)
# collect loss and metric for validation dataset
loss_history['val'].append(val_loss)
metric_history['val'].append(val_metric)
# store best model
if val_loss < best_loss:
best_loss = val_loss
best_model_wts = copy.deepcopy(model.state_dict())
# store weights into a local file
torch.save(model.state_dict(), path2weights)
print('Copied best model weights!')
# learning rate schedule
lr_scheduler.step(val_loss)
if current_lr != get_lr(opt):
print('Loading best model weights!')
model.load_state_dict(best_model_wts)
# print the loss and accuracy values and return the trained model
print('train loss: %.6f, dev loss: %.6f, accuracy: %.2f' %(train_loss, val_loss, 100 * val_metric))
print('-' * 10)
# load best model weights
model.load_state_dict(best_model_wts)
return model, loss_history, metric_history
set the sanity_check flag to True and run the code
import copy
# define the objects for the optimization, loss, and learning rate schedule
loss_func = nn.NLLLoss(reduction='sum')
opt = optim.Adam(cnn_model.parameters(), lr=3e-4)
lr_scheduler = ReduceLROnPlateau(opt, mode='min', factor=0.5, patience=20, verbose=1)
# define the training parameters and call the train_val helper function
params_train = {
'num_epochs': 100,
'optimizer': opt,
'loss_func': loss_func,
'train_dl': train_dl,
'val_dl': val_dl,
'sanity_check': True,
'lr_scheduler': lr_scheduler,
'path2weights': './models/histopathologic-cancer-detection/weights.pt'
}
# train and validate the model
cnn_model, loss_hist, metric_hist = train_val(cnn_model, params_train)
Epoch 0/99, current lr=0.0003
Copied best model weights!
train loss: 0.000125, dev loss: 0.001004, accuracy: 0.08
----------
Epoch 1/99, current lr=0.0003
Copied best model weights!
train loss: 0.000125, dev loss: 0.001002, accuracy: 0.08
----------
Epoch 2/99, current lr=0.0003
Copied best model weights!
train loss: 0.000124, dev loss: 0.001000, accuracy: 0.08
----------
Epoch 3/99, current lr=0.0003
Copied best model weights!
train loss: 0.000125, dev loss: 0.000999, accuracy: 0.08
----------
Epoch 4/99, current lr=0.0003
Copied best model weights!
train loss: 0.000126, dev loss: 0.000998, accuracy: 0.08
----------
Epoch 5/99, current lr=0.0003
Copied best model weights!
train loss: 0.000127, dev loss: 0.000998, accuracy: 0.08
----------
Epoch 6/99, current lr=0.0003
Copied best model weights!
train loss: 0.000124, dev loss: 0.000997, accuracy: 0.08
----------
Epoch 7/99, current lr=0.0003
Copied best model weights!
train loss: 0.000124, dev loss: 0.000996, accuracy: 0.08
----------
Epoch 8/99, current lr=0.0003
Copied best model weights!
train loss: 0.000126, dev loss: 0.000996, accuracy: 0.08
----------
Epoch 9/99, current lr=0.0003
Copied best model weights!
train loss: 0.000126, dev loss: 0.000995, accuracy: 0.08
----------
Epoch 10/99, current lr=0.0003
Copied best model weights!
train loss: 0.000119, dev loss: 0.000995, accuracy: 0.08
----------
Epoch 11/99, current lr=0.0003
Copied best model weights!
train loss: 0.000122, dev loss: 0.000995, accuracy: 0.08
----------
Epoch 12/99, current lr=0.0003
Copied best model weights!
train loss: 0.000119, dev loss: 0.000995, accuracy: 0.08
----------
Epoch 13/99, current lr=0.0003
train loss: 0.000132, dev loss: 0.000995, accuracy: 0.08
----------
Epoch 14/99, current lr=0.0003
train loss: 0.000119, dev loss: 0.000995, accuracy: 0.08
----------
Epoch 15/99, current lr=0.0003
train loss: 0.000111, dev loss: 0.000996, accuracy: 0.08
----------
Epoch 16/99, current lr=0.0003
train loss: 0.000131, dev loss: 0.000996, accuracy: 0.08
----------
Epoch 17/99, current lr=0.0003
train loss: 0.000119, dev loss: 0.000997, accuracy: 0.08
----------
Epoch 18/99, current lr=0.0003
train loss: 0.000122, dev loss: 0.000999, accuracy: 0.08
----------
Epoch 19/99, current lr=0.0003
train loss: 0.000118, dev loss: 0.001000, accuracy: 0.08
----------
Epoch 20/99, current lr=0.0003
train loss: 0.000135, dev loss: 0.001000, accuracy: 0.08
----------
Epoch 21/99, current lr=0.0003
train loss: 0.000120, dev loss: 0.001000, accuracy: 0.08
----------
Epoch 22/99, current lr=0.0003
train loss: 0.000127, dev loss: 0.000999, accuracy: 0.08
----------
Epoch 23/99, current lr=0.0003
train loss: 0.000109, dev loss: 0.001000, accuracy: 0.08
----------
Epoch 24/99, current lr=0.0003
train loss: 0.000133, dev loss: 0.000999, accuracy: 0.08
----------
Epoch 25/99, current lr=0.0003
train loss: 0.000121, dev loss: 0.000998, accuracy: 0.08
----------
Epoch 26/99, current lr=0.0003
train loss: 0.000131, dev loss: 0.000997, accuracy: 0.08
----------
Epoch 27/99, current lr=0.0003
train loss: 0.000123, dev loss: 0.000996, accuracy: 0.08
----------
Epoch 28/99, current lr=0.0003
train loss: 0.000125, dev loss: 0.000995, accuracy: 0.08
----------
Epoch 29/99, current lr=0.0003
Copied best model weights!
train loss: 0.000120, dev loss: 0.000994, accuracy: 0.08
----------
Epoch 30/99, current lr=0.0003
Copied best model weights!
train loss: 0.000122, dev loss: 0.000994, accuracy: 0.08
----------
Epoch 31/99, current lr=0.0003
Copied best model weights!
train loss: 0.000134, dev loss: 0.000993, accuracy: 0.08
----------
Epoch 32/99, current lr=0.0003
Copied best model weights!
train loss: 0.000122, dev loss: 0.000993, accuracy: 0.08
----------
Epoch 33/99, current lr=0.0003
Copied best model weights!
train loss: 0.000121, dev loss: 0.000993, accuracy: 0.08
----------
Epoch 34/99, current lr=0.0003
Copied best model weights!
train loss: 0.000119, dev loss: 0.000992, accuracy: 0.08
----------
Epoch 35/99, current lr=0.0003
Copied best model weights!
train loss: 0.000119, dev loss: 0.000992, accuracy: 0.08
----------
Epoch 36/99, current lr=0.0003
Copied best model weights!
train loss: 0.000120, dev loss: 0.000992, accuracy: 0.08
----------
Epoch 37/99, current lr=0.0003
Copied best model weights!
train loss: 0.000129, dev loss: 0.000992, accuracy: 0.08
----------
Epoch 38/99, current lr=0.0003
Copied best model weights!
train loss: 0.000117, dev loss: 0.000992, accuracy: 0.08
----------
Epoch 39/99, current lr=0.0003
train loss: 0.000115, dev loss: 0.000992, accuracy: 0.08
----------
Epoch 40/99, current lr=0.0003
train loss: 0.000125, dev loss: 0.000992, accuracy: 0.08
----------
Epoch 41/99, current lr=0.0003
train loss: 0.000114, dev loss: 0.000993, accuracy: 0.08
----------
Epoch 42/99, current lr=0.0003
train loss: 0.000131, dev loss: 0.000994, accuracy: 0.08
----------
Epoch 43/99, current lr=0.0003
train loss: 0.000128, dev loss: 0.000993, accuracy: 0.08
----------
Epoch 44/99, current lr=0.0003
train loss: 0.000119, dev loss: 0.000993, accuracy: 0.08
----------
Epoch 45/99, current lr=0.0003
train loss: 0.000119, dev loss: 0.000994, accuracy: 0.08
----------
Epoch 46/99, current lr=0.0003
train loss: 0.000117, dev loss: 0.000995, accuracy: 0.08
----------
Epoch 47/99, current lr=0.0003
train loss: 0.000120, dev loss: 0.000996, accuracy: 0.08
----------
Epoch 48/99, current lr=0.0003
train loss: 0.000126, dev loss: 0.000996, accuracy: 0.08
----------
Epoch 49/99, current lr=0.0003
train loss: 0.000124, dev loss: 0.000996, accuracy: 0.08
----------
Epoch 50/99, current lr=0.0003
train loss: 0.000130, dev loss: 0.000994, accuracy: 0.08
----------
Epoch 51/99, current lr=0.0003
Copied best model weights!
train loss: 0.000134, dev loss: 0.000991, accuracy: 0.08
----------
Epoch 52/99, current lr=0.0003
Copied best model weights!
train loss: 0.000117, dev loss: 0.000990, accuracy: 0.08
----------
Epoch 53/99, current lr=0.0003
Copied best model weights!
train loss: 0.000109, dev loss: 0.000990, accuracy: 0.08
----------
Epoch 54/99, current lr=0.0003
Copied best model weights!
train loss: 0.000132, dev loss: 0.000989, accuracy: 0.08
----------
Epoch 55/99, current lr=0.0003
Copied best model weights!
train loss: 0.000117, dev loss: 0.000988, accuracy: 0.08
----------
Epoch 56/99, current lr=0.0003
train loss: 0.000112, dev loss: 0.000988, accuracy: 0.08
----------
Epoch 57/99, current lr=0.0003
train loss: 0.000114, dev loss: 0.000989, accuracy: 0.08
----------
Epoch 58/99, current lr=0.0003
train loss: 0.000124, dev loss: 0.000991, accuracy: 0.08
----------
Epoch 59/99, current lr=0.0003
train loss: 0.000113, dev loss: 0.000992, accuracy: 0.08
----------
Epoch 60/99, current lr=0.0003
train loss: 0.000113, dev loss: 0.000996, accuracy: 0.08
----------
Epoch 61/99, current lr=0.0003
train loss: 0.000126, dev loss: 0.000998, accuracy: 0.08
----------
Epoch 62/99, current lr=0.0003
train loss: 0.000107, dev loss: 0.001003, accuracy: 0.08
----------
Epoch 63/99, current lr=0.0003
train loss: 0.000114, dev loss: 0.001009, accuracy: 0.08
----------
Epoch 64/99, current lr=0.0003
train loss: 0.000113, dev loss: 0.001015, accuracy: 0.08
----------
Epoch 65/99, current lr=0.0003
train loss: 0.000114, dev loss: 0.001023, accuracy: 0.08
----------
Epoch 66/99, current lr=0.0003
train loss: 0.000112, dev loss: 0.001032, accuracy: 0.08
----------
Epoch 67/99, current lr=0.0003
train loss: 0.000134, dev loss: 0.001031, accuracy: 0.08
----------
Epoch 68/99, current lr=0.0003
train loss: 0.000127, dev loss: 0.001025, accuracy: 0.08
----------
Epoch 69/99, current lr=0.0003
train loss: 0.000124, dev loss: 0.001016, accuracy: 0.08
----------
Epoch 70/99, current lr=0.0003
train loss: 0.000114, dev loss: 0.001009, accuracy: 0.08
----------
Epoch 71/99, current lr=0.0003
train loss: 0.000107, dev loss: 0.001006, accuracy: 0.08
----------
Epoch 72/99, current lr=0.0003
train loss: 0.000115, dev loss: 0.001003, accuracy: 0.08
----------
Epoch 73/99, current lr=0.0003
train loss: 0.000121, dev loss: 0.001000, accuracy: 0.08
----------
Epoch 74/99, current lr=0.0003
train loss: 0.000126, dev loss: 0.000996, accuracy: 0.08
----------
Epoch 75/99, current lr=0.0003
train loss: 0.000116, dev loss: 0.000992, accuracy: 0.08
----------
Epoch 76/99, current lr=0.0003
Epoch 77: reducing learning rate of group 0 to 1.5000e-04.
Loading best model weights!
train loss: 0.000114, dev loss: 0.000989, accuracy: 0.08
----------
Epoch 77/99, current lr=0.00015
Copied best model weights!
train loss: 0.000125, dev loss: 0.000988, accuracy: 0.08
----------
Epoch 78/99, current lr=0.00015
Copied best model weights!
train loss: 0.000118, dev loss: 0.000988, accuracy: 0.08
----------
Epoch 79/99, current lr=0.00015
Copied best model weights!
train loss: 0.000118, dev loss: 0.000987, accuracy: 0.08
----------
Epoch 80/99, current lr=0.00015
Copied best model weights!
train loss: 0.000119, dev loss: 0.000987, accuracy: 0.08
----------
Epoch 81/99, current lr=0.00015
train loss: 0.000111, dev loss: 0.000987, accuracy: 0.08
----------
Epoch 82/99, current lr=0.00015
train loss: 0.000115, dev loss: 0.000988, accuracy: 0.08
----------
Epoch 83/99, current lr=0.00015
train loss: 0.000118, dev loss: 0.000988, accuracy: 0.08
----------
Epoch 84/99, current lr=0.00015
train loss: 0.000125, dev loss: 0.000989, accuracy: 0.08
----------
Epoch 85/99, current lr=0.00015
train loss: 0.000122, dev loss: 0.000989, accuracy: 0.08
----------
Epoch 86/99, current lr=0.00015
train loss: 0.000130, dev loss: 0.000989, accuracy: 0.08
----------
Epoch 87/99, current lr=0.00015
train loss: 0.000130, dev loss: 0.000989, accuracy: 0.08
----------
Epoch 88/99, current lr=0.00015
train loss: 0.000118, dev loss: 0.000988, accuracy: 0.08
----------
Epoch 89/99, current lr=0.00015
train loss: 0.000123, dev loss: 0.000988, accuracy: 0.08
----------
Epoch 90/99, current lr=0.00015
train loss: 0.000109, dev loss: 0.000988, accuracy: 0.08
----------
Epoch 91/99, current lr=0.00015
train loss: 0.000124, dev loss: 0.000988, accuracy: 0.08
----------
Epoch 92/99, current lr=0.00015
train loss: 0.000125, dev loss: 0.000987, accuracy: 0.08
----------
Epoch 93/99, current lr=0.00015
Copied best model weights!
train loss: 0.000121, dev loss: 0.000987, accuracy: 0.08
----------
Epoch 94/99, current lr=0.00015
Copied best model weights!
train loss: 0.000130, dev loss: 0.000986, accuracy: 0.08
----------
Epoch 95/99, current lr=0.00015
Copied best model weights!
train loss: 0.000123, dev loss: 0.000986, accuracy: 0.08
----------
Epoch 96/99, current lr=0.00015
Copied best model weights!
train loss: 0.000122, dev loss: 0.000985, accuracy: 0.08
----------
Epoch 97/99, current lr=0.00015
Copied best model weights!
train loss: 0.000126, dev loss: 0.000984, accuracy: 0.08
----------
Epoch 98/99, current lr=0.00015
Copied best model weights!
train loss: 0.000119, dev loss: 0.000984, accuracy: 0.08
----------
Epoch 99/99, current lr=0.00015
Copied best model weights!
train loss: 0.000117, dev loss: 0.000983, accuracy: 0.08
----------
plot the training validation’s progress using the returned values
# Train-Validation Progress
num_epochs = params_train['num_epochs']
# plot loss progress
plt.title('Train-Val Loss')
plt.plot(range(1, num_epochs + 1), loss_hist['train'], label='train')
plt.plot(range(1, num_epochs + 1), loss_hist['val'], label='val')
plt.ylabel('Loss')
plt.xlabel('Training Epochs')
plt.legend()
plt.show()
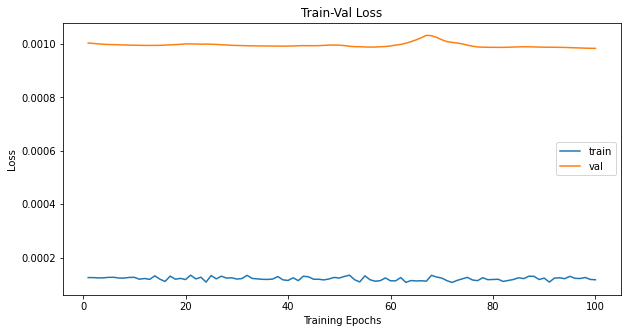
# plot accuracy progress
plt.title('Train-Val Accuracy')
plt.plot(range(1, num_epochs + 1), metric_hist['train'], label='train')
plt.plot(range(1, num_epochs + 1), metric_hist['val'], label='val')
plt.ylabel('Accuracy')
plt.xlabel('Training Epochs')
plt.legend()
plt.show()
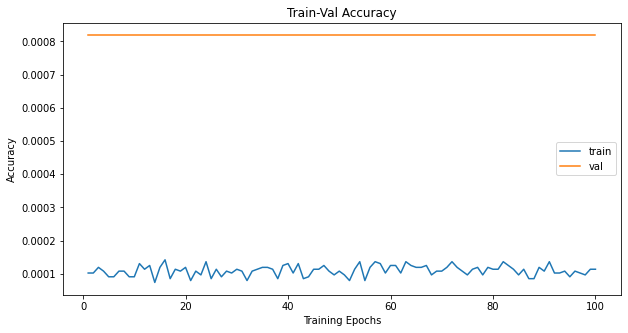
By doing this, we’ve made sure that all the elements are implemented correctly
set the flag to sanity_check: False and run the code
# define the objects for the optimization, loss, and learning rate schedule
loss_func = nn.NLLLoss(reduction='sum')
opt = optim.Adam(cnn_model.parameters(), lr=3e-4)
lr_scheduler = ReduceLROnPlateau(opt, mode='min', factor=0.5, patience=20, verbose=1)
# define the training parameters and call the train_val helper function
params_train = {
'num_epochs': 100,
'optimizer': opt,
'loss_func': loss_func,
'train_dl': train_dl,
'val_dl': val_dl,
'sanity_check': False,
'lr_scheduler': lr_scheduler,
'path2weights': './models/histopathologic-cancer-detection/weights.pt'
}
# train and validate the model
cnn_model, loss_hist, metric_hist = train_val(cnn_model, params_train)
Epoch 0/99, current lr=0.0003
Copied best model weights!
train loss: 0.431245, dev loss: 0.371016, accuracy: 84.18
----------
Epoch 1/99, current lr=0.0003
Copied best model weights!
train loss: 0.364880, dev loss: 0.336902, accuracy: 85.71
----------
Epoch 2/99, current lr=0.0003
train loss: 0.334907, dev loss: 0.348402, accuracy: 85.07
----------
Epoch 3/99, current lr=0.0003
Copied best model weights!
train loss: 0.312569, dev loss: 0.285598, accuracy: 88.26
----------
Epoch 4/99, current lr=0.0003
Copied best model weights!
train loss: 0.289273, dev loss: 0.271422, accuracy: 89.22
----------
Epoch 5/99, current lr=0.0003
Copied best model weights!
train loss: 0.273691, dev loss: 0.266002, accuracy: 89.09
----------
Epoch 6/99, current lr=0.0003
Copied best model weights!
train loss: 0.260208, dev loss: 0.259683, accuracy: 89.44
----------
Epoch 7/99, current lr=0.0003
Copied best model weights!
train loss: 0.250342, dev loss: 0.253600, accuracy: 89.58
----------
Epoch 8/99, current lr=0.0003
train loss: 0.240702, dev loss: 0.257903, accuracy: 89.54
----------
Epoch 9/99, current lr=0.0003
Copied best model weights!
train loss: 0.230366, dev loss: 0.245778, accuracy: 90.14
----------
Epoch 10/99, current lr=0.0003
Copied best model weights!
train loss: 0.221776, dev loss: 0.237988, accuracy: 90.41
----------
Epoch 11/99, current lr=0.0003
Copied best model weights!
train loss: 0.215566, dev loss: 0.218620, accuracy: 91.27
----------
Epoch 12/99, current lr=0.0003
train loss: 0.207928, dev loss: 0.220410, accuracy: 91.35
----------
Epoch 13/99, current lr=0.0003
train loss: 0.201828, dev loss: 0.233551, accuracy: 90.65
----------
Epoch 14/99, current lr=0.0003
train loss: 0.195854, dev loss: 0.220554, accuracy: 91.53
----------
Epoch 15/99, current lr=0.0003
Copied best model weights!
train loss: 0.191410, dev loss: 0.208908, accuracy: 91.93
----------
Epoch 16/99, current lr=0.0003
train loss: 0.184770, dev loss: 0.222821, accuracy: 91.24
----------
Epoch 17/99, current lr=0.0003
train loss: 0.178854, dev loss: 0.230533, accuracy: 90.86
----------
Epoch 18/99, current lr=0.0003
train loss: 0.174249, dev loss: 0.242982, accuracy: 90.92
----------
Epoch 19/99, current lr=0.0003
Copied best model weights!
train loss: 0.171158, dev loss: 0.206852, accuracy: 92.13
----------
Epoch 20/99, current lr=0.0003
train loss: 0.165627, dev loss: 0.231116, accuracy: 91.18
----------
Epoch 21/99, current lr=0.0003
train loss: 0.162174, dev loss: 0.223826, accuracy: 91.46
----------
Epoch 22/99, current lr=0.0003
train loss: 0.158736, dev loss: 0.248748, accuracy: 90.37
----------
Epoch 23/99, current lr=0.0003
train loss: 0.154363, dev loss: 0.215472, accuracy: 92.06
----------
Epoch 24/99, current lr=0.0003
train loss: 0.149600, dev loss: 0.240038, accuracy: 91.12
----------
Epoch 25/99, current lr=0.0003
train loss: 0.146160, dev loss: 0.229289, accuracy: 91.73
----------
Epoch 26/99, current lr=0.0003
train loss: 0.142025, dev loss: 0.220742, accuracy: 91.96
----------
Epoch 27/99, current lr=0.0003
train loss: 0.138858, dev loss: 0.224885, accuracy: 91.84
----------
Epoch 28/99, current lr=0.0003
train loss: 0.134581, dev loss: 0.230112, accuracy: 91.65
----------
Epoch 29/99, current lr=0.0003
train loss: 0.130833, dev loss: 0.268184, accuracy: 90.29
----------
Epoch 30/99, current lr=0.0003
train loss: 0.126733, dev loss: 0.240424, accuracy: 91.77
----------
Epoch 31/99, current lr=0.0003
train loss: 0.123765, dev loss: 0.263925, accuracy: 91.39
----------
Epoch 32/99, current lr=0.0003
train loss: 0.120903, dev loss: 0.247722, accuracy: 91.18
----------
Epoch 33/99, current lr=0.0003
train loss: 0.116467, dev loss: 0.260422, accuracy: 91.29
----------
Epoch 34/99, current lr=0.0003
train loss: 0.114482, dev loss: 0.316318, accuracy: 90.08
----------
Epoch 35/99, current lr=0.0003
train loss: 0.111843, dev loss: 0.293863, accuracy: 91.18
----------
Epoch 36/99, current lr=0.0003
train loss: 0.109624, dev loss: 0.275969, accuracy: 91.55
----------
Epoch 37/99, current lr=0.0003
train loss: 0.106616, dev loss: 0.302577, accuracy: 91.01
----------
Epoch 38/99, current lr=0.0003
train loss: 0.102099, dev loss: 0.336522, accuracy: 90.58
----------
Epoch 39/99, current lr=0.0003
train loss: 0.099404, dev loss: 0.281352, accuracy: 91.34
----------
Epoch 40/99, current lr=0.0003
Epoch 41: reducing learning rate of group 0 to 1.5000e-04.
Loading best model weights!
train loss: 0.097259, dev loss: 0.310760, accuracy: 90.27
----------
Epoch 41/99, current lr=0.00015
train loss: 0.145875, dev loss: 0.218840, accuracy: 91.76
----------
Epoch 42/99, current lr=0.00015
Copied best model weights!
train loss: 0.141646, dev loss: 0.201945, accuracy: 92.36
----------
Epoch 43/99, current lr=0.00015
train loss: 0.137608, dev loss: 0.222107, accuracy: 91.27
----------
Epoch 44/99, current lr=0.00015
train loss: 0.134138, dev loss: 0.226642, accuracy: 91.54
----------
Epoch 45/99, current lr=0.00015
train loss: 0.131223, dev loss: 0.227505, accuracy: 91.61
----------
Epoch 46/99, current lr=0.00015
train loss: 0.129436, dev loss: 0.255330, accuracy: 91.22
----------
Epoch 47/99, current lr=0.00015
train loss: 0.125385, dev loss: 0.217554, accuracy: 92.13
----------
Epoch 48/99, current lr=0.00015
train loss: 0.123121, dev loss: 0.226753, accuracy: 92.20
----------
Epoch 49/99, current lr=0.00015
train loss: 0.120240, dev loss: 0.227882, accuracy: 92.10
----------
Epoch 50/99, current lr=0.00015
train loss: 0.116732, dev loss: 0.227692, accuracy: 92.02
----------
Epoch 51/99, current lr=0.00015
train loss: 0.113933, dev loss: 0.228686, accuracy: 91.89
----------
Epoch 52/99, current lr=0.00015
train loss: 0.111389, dev loss: 0.239397, accuracy: 92.22
----------
Epoch 53/99, current lr=0.00015
train loss: 0.108908, dev loss: 0.240607, accuracy: 91.51
----------
Epoch 54/99, current lr=0.00015
train loss: 0.106407, dev loss: 0.270516, accuracy: 91.66
----------
Epoch 55/99, current lr=0.00015
train loss: 0.103311, dev loss: 0.261991, accuracy: 91.65
----------
Epoch 56/99, current lr=0.00015
train loss: 0.101603, dev loss: 0.238042, accuracy: 92.01
----------
Epoch 57/99, current lr=0.00015
train loss: 0.099041, dev loss: 0.252089, accuracy: 92.16
----------
Epoch 58/99, current lr=0.00015
train loss: 0.095353, dev loss: 0.267571, accuracy: 91.90
----------
Epoch 59/99, current lr=0.00015
train loss: 0.094050, dev loss: 0.251885, accuracy: 91.79
----------
Epoch 60/99, current lr=0.00015
train loss: 0.091214, dev loss: 0.272230, accuracy: 91.67
----------
Epoch 61/99, current lr=0.00015
train loss: 0.089355, dev loss: 0.274792, accuracy: 91.68
----------
Epoch 62/99, current lr=0.00015
train loss: 0.087199, dev loss: 0.284641, accuracy: 91.51
----------
Epoch 63/99, current lr=0.00015
Epoch 64: reducing learning rate of group 0 to 7.5000e-05.
Loading best model weights!
train loss: 0.085903, dev loss: 0.307218, accuracy: 91.28
----------
Epoch 64/99, current lr=7.5e-05
train loss: 0.126781, dev loss: 0.205718, accuracy: 92.32
----------
Epoch 65/99, current lr=7.5e-05
train loss: 0.124482, dev loss: 0.212086, accuracy: 92.26
----------
Epoch 66/99, current lr=7.5e-05
train loss: 0.121746, dev loss: 0.214526, accuracy: 92.13
----------
Epoch 67/99, current lr=7.5e-05
train loss: 0.119455, dev loss: 0.218393, accuracy: 92.36
----------
Epoch 68/99, current lr=7.5e-05
train loss: 0.117192, dev loss: 0.223504, accuracy: 91.70
----------
Epoch 69/99, current lr=7.5e-05
train loss: 0.115737, dev loss: 0.216601, accuracy: 92.56
----------
Epoch 70/99, current lr=7.5e-05
train loss: 0.113825, dev loss: 0.213886, accuracy: 92.28
----------
Epoch 71/99, current lr=7.5e-05
train loss: 0.111628, dev loss: 0.222195, accuracy: 92.36
----------
Epoch 72/99, current lr=7.5e-05
train loss: 0.109355, dev loss: 0.221932, accuracy: 92.42
----------
Epoch 73/99, current lr=7.5e-05
train loss: 0.108085, dev loss: 0.227627, accuracy: 91.78
----------
Epoch 74/99, current lr=7.5e-05
train loss: 0.105904, dev loss: 0.224645, accuracy: 92.40
----------
Epoch 75/99, current lr=7.5e-05
train loss: 0.104035, dev loss: 0.231799, accuracy: 92.27
----------
Epoch 76/99, current lr=7.5e-05
train loss: 0.102371, dev loss: 0.236154, accuracy: 92.13
----------
Epoch 77/99, current lr=7.5e-05
train loss: 0.100476, dev loss: 0.230616, accuracy: 92.27
----------
Epoch 78/99, current lr=7.5e-05
train loss: 0.097894, dev loss: 0.241470, accuracy: 92.00
----------
Epoch 79/99, current lr=7.5e-05
train loss: 0.096778, dev loss: 0.244693, accuracy: 92.14
----------
Epoch 80/99, current lr=7.5e-05
train loss: 0.095305, dev loss: 0.248013, accuracy: 92.23
----------
Epoch 81/99, current lr=7.5e-05
train loss: 0.093307, dev loss: 0.251737, accuracy: 91.85
----------
Epoch 82/99, current lr=7.5e-05
train loss: 0.091592, dev loss: 0.283506, accuracy: 91.79
----------
Epoch 83/99, current lr=7.5e-05
train loss: 0.090138, dev loss: 0.254773, accuracy: 91.99
----------
Epoch 84/99, current lr=7.5e-05
Epoch 85: reducing learning rate of group 0 to 3.7500e-05.
Loading best model weights!
train loss: 0.087786, dev loss: 0.258594, accuracy: 91.81
----------
Epoch 85/99, current lr=3.75e-05
train loss: 0.122277, dev loss: 0.209819, accuracy: 92.46
----------
Epoch 86/99, current lr=3.75e-05
train loss: 0.119932, dev loss: 0.207946, accuracy: 92.55
----------
Epoch 87/99, current lr=3.75e-05
train loss: 0.118412, dev loss: 0.210325, accuracy: 92.53
----------
Epoch 88/99, current lr=3.75e-05
train loss: 0.117008, dev loss: 0.211478, accuracy: 92.33
----------
Epoch 89/99, current lr=3.75e-05
train loss: 0.115552, dev loss: 0.211000, accuracy: 92.54
----------
Epoch 90/99, current lr=3.75e-05
train loss: 0.113914, dev loss: 0.213650, accuracy: 92.19
----------
Epoch 91/99, current lr=3.75e-05
train loss: 0.112591, dev loss: 0.214389, accuracy: 92.49
----------
Epoch 92/99, current lr=3.75e-05
train loss: 0.111089, dev loss: 0.220045, accuracy: 92.34
----------
Epoch 93/99, current lr=3.75e-05
train loss: 0.110250, dev loss: 0.217634, accuracy: 92.20
----------
Epoch 94/99, current lr=3.75e-05
10. Deploying the model
construct an object of the model class and load the weights into the model
Create an object of the Net class and load the stored weights into the model
# model parameters
params_model = {
'input_shape': (3, 96, 96),
'initial_filters': 8,
'num_fc1': 100,
'dropout_rate': 0.25,
'num_classes': 2,
}
# initialize model
cnn_model = Net(params_model)
load state_dict into model
# load state_dict into model
path2weights = './models/histopathologic-cancer-detection/weights.pt'
cnn_model.load_state_dict(torch.load(path2weights))
<All keys matched successfully>
set the model in eval mode
# set model in evaluation mode
cnn_model.eval()
Net(
(conv1): Conv2d(3, 8, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(8, 16, kernel_size=(3, 3), stride=(1, 1))
(conv3): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1))
(conv4): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=1024, out_features=100, bias=True)
(fc2): Linear(in_features=100, out_features=2, bias=True)
)
move the model onto a CUDA device if one’s available
# move model to cuda/gpu device
if torch.cuda.is_available():
device = torch.device('cuda')
cnn_model = cnn_model.to(device)
device = torch.device('cpu')
develop a helper function to deploy the model on a dataset
# define the deploy_model function
def deploy_model(model, dataset, device, num_classes=2, sanity_check=False):
len_data = len(dataset)
# initialize output tensor on CPU: due to GPU memory limits
y_out = torch.zeros(len_data, num_classes)
# initailize ground truth on CPU: due to GPU memory limits
y_gt = np.zeros((len_data), dtype='uint8')
# move model to device
# model = model.to(device)
elapsed_times = []
with torch.no_grad():
for i in range(len_data):
x, y = dataset[i]
y_gt[i] = y
start = time.time()
# y_out[i] = model(x.unsqueeze(0).to(device))
y_out[i] = model(x.unsqueeze(0))
elapsed = time.time() - start
elapsed_times.append(elapsed)
if sanity_check is True:
break
inference_time = np.mean(elapsed_times) * 1000
print('average inference time per image on %s: %.2f ms ' %(device, inference_time))
return y_out.numpy(), y_gt
use the helper function to deploy the model on the validation dataset
# deploy model
y_out, y_gt = deploy_model(cnn_model, val_ds, device=device, sanity_check=False)
print(y_out.shape, y_gt.shape)
average inference time per image on cpu: 1.78 ms
(44005, 2) (44005,)
calculate the accuracy of the model on the validation dataset using the predicted outputs
from sklearn.metrics import accuracy_score
# get predictions
y_pred = np.argmax(y_out, axis=1)
print(y_pred.shape, y_gt.shape)
(44005,) (44005,)
# compute accuracy
acc = accuracy_score(y_pred, y_gt)
print('accuracy: %.2f' %acc)
accuracy: 0.92
11. Model inference on test data
deploy the model on the test dataset
- cannot evaluate the model performance on the test dataset(labels are not available)
load test_labels.csv and print out its head
path2csv = './data/histopathologic-cancer-detection/test_labels.csv'
labels_df = pd.read_csv(path2csv)
labels_df.head()
| id | label | |
|---|---|---|
| 0 | 0b2ea2a822ad23fdb1b5dd26653da899fbd2c0d5 | 0 |
| 1 | 95596b92e5066c5c52466c90b69ff089b39f2737 | 0 |
| 2 | 248e6738860e2ebcf6258cdc1f32f299e0c76914 | 0 |
| 3 | 2c35657e312966e9294eac6841726ff3a748febf | 0 |
| 4 | 145782eb7caa1c516acbe2eda34d9a3f31c41fd6 | 0 |
create a dataset object for the test dataset
histo_test = histoCancerDataset(data_dir, val_transformer, data_type='test')
print(len(histo_test))
57458
deploy the model on the test dataset
y_test_out, _ = deploy_model(cnn_model, histo_test, device, sanity_check=False)
average inference time per image on cpu: 1.84 ms
y_test_pred = np.argmax(y_test_out, axis=1)
print(y_test_pred.shape)
(57458,)
display a few images and predictions
grid_size = 4
rnd_inds = np.random.randint(0, len(histo_test), grid_size)
print('image indices:', rnd_inds)
image indices: [ 2732 43567 42613 52416]
x_grid_test = [histo_test[i][0] for i in range(grid_size)]
y_grid_test = [y_test_pred[i] for i in range(grid_size)]
x_grid_test = utils.make_grid(x_grid_test, nrow=4, padding=2)
print(x_grid_test.shape)
torch.Size([3, 100, 394])
plt.rcParams['figure.figsize'] = (10.0, 5)
show(x_grid_test, y_grid_test)
extract the prediction probabilities from the outputs
perform the exponential function on the model outputs to convert them into probability values
print(y_test_out.shape)
cancer_preds = np.exp(y_test_out[:, 1])
print(cancer_preds.shape)
(57458, 2)
(57458,)
convert the prediction probabilities into a DataFrame and store them as a csv file
path2sampleSub = './data/histopathologic-cancer-detection/' + 'sample_submission.csv'
sample_df = pd.read_csv(path2sampleSub)
sample_df.head()
| id | label | |
|---|---|---|
| 0 | 0b2ea2a822ad23fdb1b5dd26653da899fbd2c0d5 | 0 |
| 1 | 95596b92e5066c5c52466c90b69ff089b39f2737 | 0 |
| 2 | 248e6738860e2ebcf6258cdc1f32f299e0c76914 | 0 |
| 3 | 2c35657e312966e9294eac6841726ff3a748febf | 0 |
| 4 | 145782eb7caa1c516acbe2eda34d9a3f31c41fd6 | 0 |
cancer_preds
array([8.4170753e-01, 2.5076480e-03, 7.6131680e-04, ..., 5.7613230e-01,
2.3444753e-05, 9.5456076e-01], dtype=float32)
os.listdir(data_dir + 'test')[0][:-4]
'fd0a060ef9c30c9a83f6b4bfb568db74b099154d'
ids_list = list(sample_df.id)
pred_list = [p for p in cancer_preds]
pred_dic = dict((key[:-4], value) for (key, value) in zip(os.listdir(data_dir + 'test'), pred_list))
pred_list_sub = [pred_dic[id_] for id_ in ids_list]
submission_df = pd.DataFrame({'id':ids_list, 'label':pred_list_sub})
submission_df
| id | label | |
|---|---|---|
| 0 | 0b2ea2a822ad23fdb1b5dd26653da899fbd2c0d5 | 0.003761 |
| 1 | 95596b92e5066c5c52466c90b69ff089b39f2737 | 0.821905 |
| 2 | 248e6738860e2ebcf6258cdc1f32f299e0c76914 | 0.000002 |
| 3 | 2c35657e312966e9294eac6841726ff3a748febf | 0.055766 |
| 4 | 145782eb7caa1c516acbe2eda34d9a3f31c41fd6 | 0.434647 |
| ... | ... | ... |
| 57453 | 061847314ded6f81e1cd670748bfa2003442c9c7 | 0.067737 |
| 57454 | 6f3977130212641fd5808210015a609c658dcbff | 0.000729 |
| 57455 | 46935f247278539eca74b54d07d666efb528a753 | 0.000013 |
| 57456 | a09bcae08a82120183352e0e869181b2911d3dc1 | 0.003118 |
| 57457 | d29233dc0b90c2e1a8fcedbc3e1234c3d4dbd55b | 0.002758 |
57458 rows × 2 columns
if not os.path.exists('./data/histopathologic-cancer-detection/submissions/'):
os.makedirs('data/histopathologic-cancer-detection/submissions/')
print('submission folder created!')
submission folder created!
path2submission = './data/histopathologic-cancer-detection/submissions/submission.csv'
submission_df.to_csv(path2submission, header=True, index=False)
submission_df.head()
| id | label | |
|---|---|---|
| 0 | 0b2ea2a822ad23fdb1b5dd26653da899fbd2c0d5 | 0.003761 |
| 1 | 95596b92e5066c5c52466c90b69ff089b39f2737 | 0.821905 |
| 2 | 248e6738860e2ebcf6258cdc1f32f299e0c76914 | 0.000002 |
| 3 | 2c35657e312966e9294eac6841726ff3a748febf | 0.055766 |
| 4 | 145782eb7caa1c516acbe2eda34d9a3f31c41fd6 | 0.434647 |