1. Predictive Modeling
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import konlpy
import konlpy.tag
import re
from konlpy.tag import Okt
from datetime import datetime
from tqdm import tqdm
from sklearn.decomposition import TruncatedSVD
from sklearn.preprocessing import RobustScaler
%matplotlib inline
# 한글 폰트
plt.rc('font', family='Malgun Gothic')
# 도화지 크기
plt.rcParams['figure.figsize'] = (10, 7)
# 숫자 표기법 변환
pd.set_option('display.float_format', '{:.2f}'.format)
/usr/local/lib/python3.6/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
import pandas.util.testing as tm
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
1. 데이터 셋 만들기
train = pd.read_csv("/content/drive/Shared drives/빅콘테스트2020/data/data/01_제공데이터/train.csv")
test = pd.read_csv("/content/drive/Shared drives/빅콘테스트2020/data/data/02_평가데이터/test.csv")
# column name 변경
train.columns = train.iloc[0]
test.columns = test.iloc[0]
# 첫번쨰 행 삭제
train.drop([0], axis=0, inplace=True)
test.drop([0], axis=0, inplace=True)
train
| 방송일시 | 노출(분) | 마더코드 | 상품코드 | 상품명 | 상품군 | 판매단가 | 취급액 | |
|---|---|---|---|---|---|---|---|---|
| 1 | 2019-01-01 6:00 | 20 | 100346 | 201072 | 테이트 남성 셀린니트3종 | 의류 | 39,900 | 2,099,000 |
| 2 | 2019-01-01 6:00 | NaN | 100346 | 201079 | 테이트 여성 셀린니트3종 | 의류 | 39,900 | 4,371,000 |
| 3 | 2019-01-01 6:20 | 20 | 100346 | 201072 | 테이트 남성 셀린니트3종 | 의류 | 39,900 | 3,262,000 |
| 4 | 2019-01-01 6:20 | NaN | 100346 | 201079 | 테이트 여성 셀린니트3종 | 의류 | 39,900 | 6,955,000 |
| 5 | 2019-01-01 6:40 | 20 | 100346 | 201072 | 테이트 남성 셀린니트3종 | 의류 | 39,900 | 6,672,000 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 38305 | 2020-01-01 0:20 | 20 | 100073 | 200196 | 삼성화재 행복한파트너 주택화재보험(1912) | 무형 | - | NaN |
| 38306 | 2020-01-01 0:40 | 20 | 100073 | 200196 | 삼성화재 행복한파트너 주택화재보험(1912) | 무형 | - | NaN |
| 38307 | 2020-01-01 1:00 | 20 | 100073 | 200196 | 삼성화재 행복한파트너 주택화재보험(1912) | 무형 | - | NaN |
| 38308 | 2020-01-01 1:20 | 20 | 100490 | 201478 | 더케이 예다함 상조서비스(티포트) | 무형 | - | NaN |
| 38309 | 2020-01-01 1:40 | 17 | 100490 | 201478 | 더케이 예다함 상조서비스(티포트) | 무형 | - | NaN |
38309 rows × 8 columns
test
| 방송일시 | 노출(분) | 마더코드 | 상품코드 | 상품명 | 상품군 | 판매단가 | 취급액 | |
|---|---|---|---|---|---|---|---|---|
| 1 | 2020-06-01 6:20 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | 59,800 | NaN |
| 2 | 2020-06-01 6:40 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | 59,800 | NaN |
| 3 | 2020-06-01 7:00 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | 59,800 | NaN |
| 4 | 2020-06-01 7:20 | 20 | 100445 | 202278 | 쿠미투니카 쿨 레이시 란쥬쉐이퍼&팬티 | 속옷 | 69,900 | NaN |
| 5 | 2020-06-01 7:40 | 20 | 100445 | 202278 | 쿠미투니카 쿨 레이시 란쥬쉐이퍼&팬티 | 속옷 | 69,900 | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2887 | 2020-07-01 0:20 | 20 | 100660 | 201989 | 쉴렉스 안마의자 렌탈서비스 | 무형 | - | NaN |
| 2888 | 2020-07-01 0:40 | 20 | 100660 | 201989 | 쉴렉스 안마의자 렌탈서비스 | 무형 | - | NaN |
| 2889 | 2020-07-01 1:00 | 20 | 100660 | 201989 | 쉴렉스 안마의자 렌탈서비스 | 무형 | - | NaN |
| 2890 | 2020-07-01 1:20 | 20 | 100261 | 200875 | 아놀드파마 티셔츠레깅스세트 | 의류 | 69,900 | NaN |
| 2891 | 2020-07-01 1:40 | 16 | 100261 | 200875 | 아놀드파마 티셔츠레깅스세트 | 의류 | 69,900 | NaN |
2891 rows × 8 columns
# 무형 판매단가 0으로 대입
test['판매단가'] = ['0' if x == ' - ' else x for x in test['판매단가']]
test
| 방송일시 | 노출(분) | 마더코드 | 상품코드 | 상품명 | 상품군 | 판매단가 | 취급액 | |
|---|---|---|---|---|---|---|---|---|
| 1 | 2020-06-01 6:20 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | 59,800 | NaN |
| 2 | 2020-06-01 6:40 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | 59,800 | NaN |
| 3 | 2020-06-01 7:00 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | 59,800 | NaN |
| 4 | 2020-06-01 7:20 | 20 | 100445 | 202278 | 쿠미투니카 쿨 레이시 란쥬쉐이퍼&팬티 | 속옷 | 69,900 | NaN |
| 5 | 2020-06-01 7:40 | 20 | 100445 | 202278 | 쿠미투니카 쿨 레이시 란쥬쉐이퍼&팬티 | 속옷 | 69,900 | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2887 | 2020-07-01 0:20 | 20 | 100660 | 201989 | 쉴렉스 안마의자 렌탈서비스 | 무형 | 0 | NaN |
| 2888 | 2020-07-01 0:40 | 20 | 100660 | 201989 | 쉴렉스 안마의자 렌탈서비스 | 무형 | 0 | NaN |
| 2889 | 2020-07-01 1:00 | 20 | 100660 | 201989 | 쉴렉스 안마의자 렌탈서비스 | 무형 | 0 | NaN |
| 2890 | 2020-07-01 1:20 | 20 | 100261 | 200875 | 아놀드파마 티셔츠레깅스세트 | 의류 | 69,900 | NaN |
| 2891 | 2020-07-01 1:40 | 16 | 100261 | 200875 | 아놀드파마 티셔츠레깅스세트 | 의류 | 69,900 | NaN |
2891 rows × 8 columns
# test 원본 데이터 복제
real_test = test.copy()
2. 데이터 전처리
train, test
train.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 38309 entries, 1 to 38309
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 방송일시 38309 non-null object
1 노출(분) 21525 non-null object
2 마더코드 38309 non-null object
3 상품코드 38309 non-null object
4 상품명 38309 non-null object
5 상품군 38309 non-null object
6 판매단가 38309 non-null object
7 취급액 35379 non-null object
dtypes: object(8)
memory usage: 2.6+ MB
test.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2891 entries, 1 to 2891
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 방송일시 2891 non-null object
1 노출(분) 1780 non-null object
2 마더코드 2891 non-null object
3 상품코드 2891 non-null object
4 상품명 2891 non-null object
5 상품군 2891 non-null object
6 판매단가 2891 non-null object
7 취급액 0 non-null object
dtypes: object(8)
memory usage: 203.3+ KB
train.head()
| 방송일시 | 노출(분) | 마더코드 | 상품코드 | 상품명 | 상품군 | 판매단가 | 취급액 | |
|---|---|---|---|---|---|---|---|---|
| 1 | 2019-01-01 6:00 | 20 | 100346 | 201072 | 테이트 남성 셀린니트3종 | 의류 | 39,900 | 2,099,000 |
| 2 | 2019-01-01 6:00 | NaN | 100346 | 201079 | 테이트 여성 셀린니트3종 | 의류 | 39,900 | 4,371,000 |
| 3 | 2019-01-01 6:20 | 20 | 100346 | 201072 | 테이트 남성 셀린니트3종 | 의류 | 39,900 | 3,262,000 |
| 4 | 2019-01-01 6:20 | NaN | 100346 | 201079 | 테이트 여성 셀린니트3종 | 의류 | 39,900 | 6,955,000 |
| 5 | 2019-01-01 6:40 | 20 | 100346 | 201072 | 테이트 남성 셀린니트3종 | 의류 | 39,900 | 6,672,000 |
test.head()
| 방송일시 | 노출(분) | 마더코드 | 상품코드 | 상품명 | 상품군 | 판매단가 | 취급액 | |
|---|---|---|---|---|---|---|---|---|
| 1 | 2020-06-01 6:20 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | 59,800 | NaN |
| 2 | 2020-06-01 6:40 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | 59,800 | NaN |
| 3 | 2020-06-01 7:00 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | 59,800 | NaN |
| 4 | 2020-06-01 7:20 | 20 | 100445 | 202278 | 쿠미투니카 쿨 레이시 란쥬쉐이퍼&팬티 | 속옷 | 69,900 | NaN |
| 5 | 2020-06-01 7:40 | 20 | 100445 | 202278 | 쿠미투니카 쿨 레이시 란쥬쉐이퍼&팬티 | 속옷 | 69,900 | NaN |
column name 변경
train.columns
Index(['방송일시', '노출(분)', '마더코드', '상품코드', '상품명', '상품군', '판매단가', ' 취급액 '], dtype='object', name=0)
test.columns
Index(['방송일시', '노출(분)', '마더코드', '상품코드', '상품명', '상품군', '판매단가', '취급액'], dtype='object', name=0)
train.rename({' 취급액 ':'취급액'}, axis=1, inplace=True)
판매단가, 취급액 타입 변경
# 쉼표 제거
train['취급액'] = [x.replace(',','').strip() if str(type(x)) != "<class 'float'>" else x for x in train['취급액']]
train['판매단가'] = [x.replace(',','').strip() for x in train['판매단가']]
test['판매단가'] = [x.replace(',','').strip() for x in test['판매단가']]
# 취급액 NaN 제거
train = train[~train['취급액'].isna()]
train = train.reset_index().drop(['index'], axis=1)
# 판매단가, 취급액 int로 변환
train['판매단가'] = [int(x) for x in train['판매단가']]
train['취급액'] = [int(x) for x in train['취급액']]
test['판매단가'] = [int(x) for x in test['판매단가']]
방송일시 column을 바탕으로 날짜, 시, 분 column 만들기
# 날짜 column 생성
train['날짜'] = [x[:10] for x in train['방송일시']]
train['날짜'] = [datetime.strptime(x, '%Y-%m-%d') for x in train['날짜']]
test['날짜'] = [x[:10] for x in test['방송일시']]
test['날짜'] = [datetime.strptime(x, '%Y-%m-%d') for x in test['날짜']]
# 방송일시 date type변경
train['방송일시'] = [datetime.strptime(x, '%Y-%m-%d %H:%M') for x in train['방송일시']]
test['방송일시'] = [datetime.strptime(x, '%Y-%m-%d %H:%M') for x in test['방송일시']]
train['시'] = [x.hour for x in train['방송일시']]
test['시'] = [x.hour for x in test['방송일시']]
train['분'] = [x.minute for x in train['방송일시']]
test['분'] = [x.minute for x in test['방송일시']]
final = train.set_index('날짜')
temp = final.pivot_table(index='시', columns='상품군', aggfunc='mean', values='취급액')
요일 column 만들기
mon = pd.date_range(start='20190101', end='20200701', freq='W-MON')
tue = pd.date_range(start='20190101', end='20200701', freq='W-TUE')
wed = pd.date_range(start='20190101', end='20200701', freq='W-WED')
thu = pd.date_range(start='20190101', end='20200701', freq='W-THU')
fri = pd.date_range(start='20190101', end='20200701', freq='W-FRI')
sat = pd.date_range(start='20190101', end='20200701', freq='W-SAT')
sun = pd.date_range(start='20190101', end='20200701', freq='W-SUN')
lst = []
for i in tqdm(range(train.shape[0])):
temp = str(train.iloc[i]['날짜'])[:10]
if temp in mon:
lst.append('1')
elif temp in tue:
lst.append('2')
elif temp in wed:
lst.append('3')
elif temp in thu:
lst.append('4')
elif temp in fri:
lst.append('5')
elif temp in sat:
lst.append('6')
else:
lst.append('7')
train['요일'] = lst
lst2 = []
for i in tqdm(range(test.shape[0])):
temp = str(test.iloc[i]['날짜'])[:10]
if temp in mon:
lst2.append('1')
elif temp in tue:
lst2.append('2')
elif temp in wed:
lst2.append('3')
elif temp in thu:
lst2.append('4')
elif temp in fri:
lst2.append('5')
elif temp in sat:
lst2.append('6')
else:
lst2.append('7')
test['요일'] = lst2
100%|██████████| 35379/35379 [00:28<00:00, 1254.83it/s]
100%|██████████| 2891/2891 [00:02<00:00, 1216.80it/s]
sns.countplot(train['요일'])
<matplotlib.axes._subplots.AxesSubplot at 0x7f7a100ab5f8>
findfont: Font family ['NanumBarunGothic'] not found. Falling back to DejaVu Sans.
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 50836 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 51068 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 50836 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 51068 missing from current font.
font.set_text(s, 0, flags=flags)
sns.countplot(test['요일'])
<matplotlib.axes._subplots.AxesSubplot at 0x7f7a12bcc5f8>
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 50836 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 51068 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 50836 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 51068 missing from current font.
font.set_text(s, 0, flags=flags)
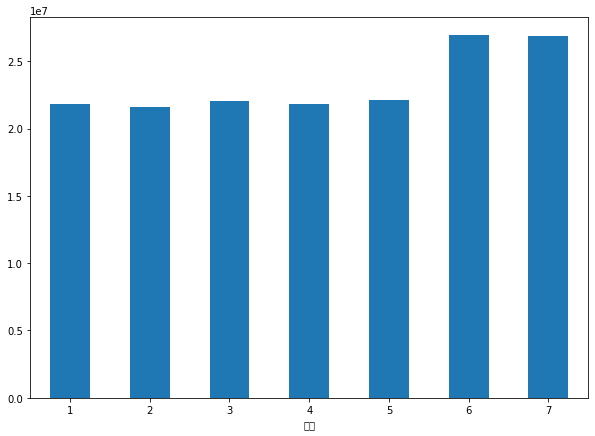
final = train.set_index('날짜')
temp = final.pivot_table(index='요일', columns='상품군', aggfunc='mean', values='취급액')
temp.mean(axis=1).plot(kind='bar', rot=0)
<matplotlib.axes._subplots.AxesSubplot at 0x7f7a100920b8>
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 50836 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 51068 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 50836 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 51068 missing from current font.
font.set_text(s, 0, flags=flags)
휴일변수 생성
공휴일이 평일보다 판매수익이 더 높을까?
* 공휴일에 상품 평균 판매수익이 더 높다
final = train.set_index('날짜')
# 2019
all_day = pd.date_range(start='20190101', end='20200101', freq='D').tolist()
all_day = [str(x)[:10] for x in all_day]
# 평일
weekday = pd.date_range(start='20190101', end='20200101', freq='B').tolist()
weekday = [str(x)[:10] for x in weekday]
# 평일 중 공휴일
holiday = ['2019-01-01', '2019-02-04', '2019-02-05', '2019-02-06', '2019-03-01',
'2019-05-06', '2019-06-06', '2019-08-15', '2019-09-12', '2019-09-13',
'2019-10-03', '2019-10-09', '2019-12-25']
weekday_revenue = 0
weekday_count = 0
holiday_revenue = 0
holiday_count = 0
for i in tqdm(all_day):
temp = final.loc[i]['취급액']
if i in weekday:
if i in holiday:
holiday_revenue += temp.sum()
holiday_count += len(temp)
else:
weekday_revenue += temp.sum()
weekday_count += len(temp)
else:
holiday_revenue += temp.sum()
holiday_count += len(temp)
100%|██████████| 366/366 [00:29<00:00, 12.26it/s]
holiday_mean_revenue = holiday_revenue / holiday_count
weekday_mean_revenue = weekday_revenue / weekday_count
temp = pd.DataFrame(np.zeros((2, 1)))
temp.loc[0] = holiday_mean_revenue
temp.loc[1] = weekday_mean_revenue
temp.index=['주말', '평일']
temp.rename({0:'평균취급액'}, axis=1, inplace=True)
temp.plot(kind='bar', rot=0)
<matplotlib.axes._subplots.AxesSubplot at 0x7f7a12acbda0>
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 51452 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 47568 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 54217 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 51068 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 51452 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 47568 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 54217 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 51068 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 44512 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 52712 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 44553 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 50529 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 44512 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 52712 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 44553 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 50529 missing from current font.
font.set_text(s, 0, flags=flags)
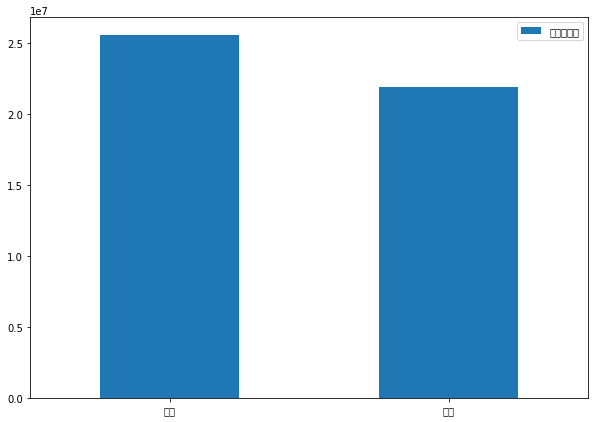
sat = pd.date_range(start='20190101', end='20200701', freq='W-SAT')
sat = [str(x)[:10] for x in sat]
sun = pd.date_range(start='20190101', end='20200701', freq='W-SUN')
sun = [str(x)[:10] for x in sun]
holiday = ['2019-01-01', '2019-02-04', '2019-02-05', '2019-02-06', '2019-03-01',
'2019-05-06', '2019-06-06', '2019-08-15', '2019-09-12', '2019-09-13',
'2019-10-03', '2019-10-09', '2019-12-25', '2020-06-06']
sat.extend(sun)
holiday.extend(sat)
lst = []
for i in tqdm(range(train.shape[0])):
temp = str(train.iloc[i]['날짜'])[:10]
if temp in holiday:
lst.append(1)
else:
lst.append(0)
train['휴일'] = lst
lst2 = []
for i in tqdm(range(test.shape[0])):
temp = str(test.iloc[i]['날짜'])[:10]
if temp in holiday:
lst2.append(1)
else:
lst2.append(0)
test['휴일'] = lst2
100%|██████████| 35379/35379 [00:06<00:00, 5134.92it/s]
100%|██████████| 2891/2891 [00:00<00:00, 4524.75it/s]
상품명 양 끝에 공백 문자 제거
train['상품명'] = [x.strip() for x in train['상품명']]
test['상품명'] = [x.strip() for x in test['상품명']]
노출(분) 시간 채우기
노출시간 NA값을 보면 전에 상품과 동시방영이라 위에 있는 값으로 채운다
dtype = train.dtypes
n_na = train.isna().sum(axis=0).tolist()
pct_na = (train.isna().sum(axis=0)*100 / train.shape[0]).tolist()
dic = {'dtype':dtype, 'NA개수':n_na, 'NA비율':pct_na}
pd.DataFrame(dic).T
| 방송일시 | 노출(분) | 마더코드 | 상품코드 | 상품명 | 상품군 | 판매단가 | 취급액 | 날짜 | 시 | 분 | 요일 | 휴일 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dtype | datetime64[ns] | object | object | object | object | object | int64 | int64 | datetime64[ns] | int64 | int64 | object | int64 |
| NA개수 | 0 | 14976 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| NA비율 | 0.00 | 42.33 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
# NaN값 미리 0으로 채워놓기
train['노출(분)'].fillna(0, inplace=True)
test['노출(분)'].fillna(0, inplace=True)
# int형으로 type 변경
train['노출(분)'] = train['노출(분)'].astype('int')
test['노출(분)'] = test['노출(분)'].astype('int')
lst = [train.iloc[0]['노출(분)']]
# 채우려는 값
fill = train.iloc[0]['노출(분)']
for i in tqdm(range(1, train.shape[0])):
# 값이 존재하면 채우려는 값을 바꿔준다
if train.iloc[i]['노출(분)'] != 0:
fill = train.iloc[i]['노출(분)']
lst.append(fill)
# 값이 없으면 현재의 fill값으로 채운다
else:
lst.append(fill)
train['노출(분)'] = lst
100%|██████████| 35378/35378 [00:10<00:00, 3326.30it/s]
lst = [test.iloc[0]['노출(분)']]
# 채우려는 값
fill = test.iloc[0]['노출(분)']
for i in tqdm(range(1, test.shape[0])):
# 값이 존재하면 채우려는 값을 바꿔준다
if test.iloc[i]['노출(분)'] != 0:
fill = test.iloc[i]['노출(분)']
lst.append(fill)
# 값이 없으면 현재의 fill값으로 채운다
else:
lst.append(fill)
test['노출(분)'] = lst
100%|██████████| 2890/2890 [00:01<00:00, 2807.89it/s]
계절 변수 생성
spring = ['03', '04', '05']
summer = ['06', '07', '08']
fall = ['9', '10', '11']
winter = ['12', '01', '02']
season = []
for i in tqdm(range(train.shape[0])):
if str(train.iloc[i,0])[5:7] in spring:
season.append(0)
elif str(train.iloc[i,0])[5:7] in summer:
season.append(1)
elif str(train.iloc[i,0])[5:7] in fall:
season.append(2)
else:
season.append(3)
train['season'] = season
season2 = []
for i in tqdm(range(test.shape[0])):
if str(test.iloc[i,0])[5:7] in spring:
season2.append(0)
elif str(test.iloc[i,0])[5:7] in summer:
season2.append(1)
elif str(test.iloc[i,0])[5:7] in fall:
season2.append(2)
else:
season2.append(3)
test['season'] = season2
100%|██████████| 35379/35379 [00:00<00:00, 36338.03it/s]
100%|██████████| 2891/2891 [00:00<00:00, 39906.84it/s]
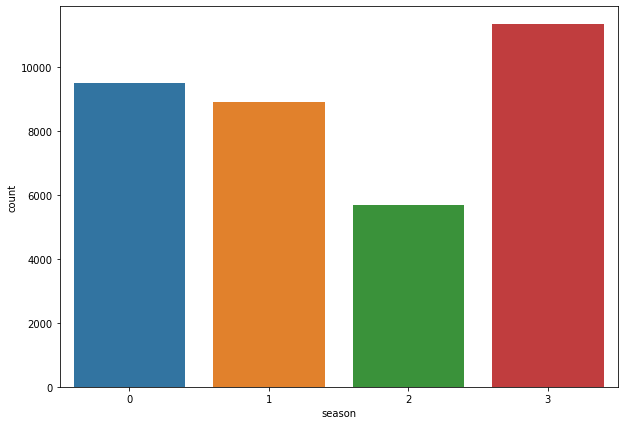
sns.countplot(train['season'])
<matplotlib.axes._subplots.AxesSubplot at 0x7f7a12a63898>
1일 기준으로 해당상품 노출 횟수
cnt = []
for i in tqdm(train['날짜'].value_counts().sort_index().index.tolist()):
temp = train[train['날짜'] == i]
dic = {}
for i in range(temp.shape[0]):
temp2 = temp.iloc[i]['상품명']
if dic.get(temp2) == None:
dic[temp2] = 1
else:
dic[temp2] += 1
cnt.append(dic[temp2])
train['노출횟수'] = cnt
100%|██████████| 366/366 [00:06<00:00, 54.22it/s]
cnt = []
for i in tqdm(test['날짜'].value_counts().sort_index().index.tolist()):
temp = test[test['날짜'] == i]
dic = {}
for i in range(temp.shape[0]):
temp2 = temp.iloc[i]['상품명']
if dic.get(temp2) == None:
dic[temp2] = 1
else:
dic[temp2] += 1
cnt.append(dic[temp2])
test['노출횟수'] = cnt
100%|██████████| 31/31 [00:00<00:00, 58.45it/s]
주문량 변수 만들기
train['주문량'] = train['취급액'] / train['판매단가']
판매단가등급 column 만들기
평균판매단가가 낮을수록 더 많이 팔렸다
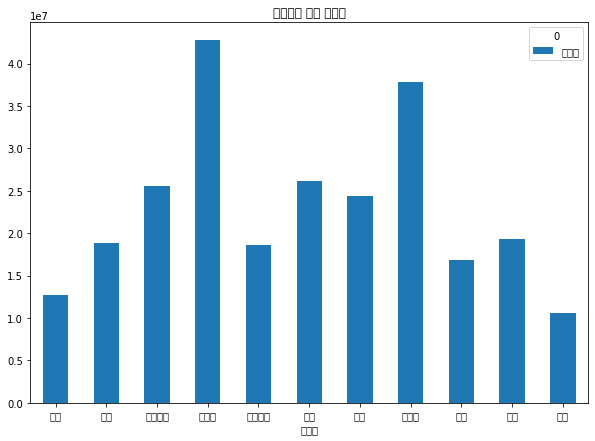
final.pivot_table(index='상품군', aggfunc='mean', values='취급액').plot(kind='bar', rot=0)
plt.title('상품군별 평균 취급액')
Text(0.5, 1.0, '상품군별 평균 취급액')
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 49345 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 54408 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 44400 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 48324 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 54217 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 44512 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 52712 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 44553 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 50529 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 44032 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 44396 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 51204 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 44148 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 44053 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 44592 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 45733 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 45453 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 49688 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 52629 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 49373 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 54876 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 50857 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 49549 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 50743 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 51032 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 47448 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 51060 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 48120 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 51105 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 54868 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 51452 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 48169 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:214: RuntimeWarning: Glyph 52840 missing from current font.
font.set_text(s, 0.0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 44032 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 44396 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 51204 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 44148 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 44053 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 44592 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 45733 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 45453 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 49688 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 52629 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 49373 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 54876 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 50857 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 54408 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 49549 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 50743 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 51032 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 47448 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 51060 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 48120 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 51105 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 54868 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 51452 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 48169 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 52840 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 49345 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 44400 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 48324 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 54217 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 44512 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 52712 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 44553 missing from current font.
font.set_text(s, 0, flags=flags)
/usr/local/lib/python3.6/dist-packages/matplotlib/backends/backend_agg.py:183: RuntimeWarning: Glyph 50529 missing from current font.
font.set_text(s, 0, flags=flags)
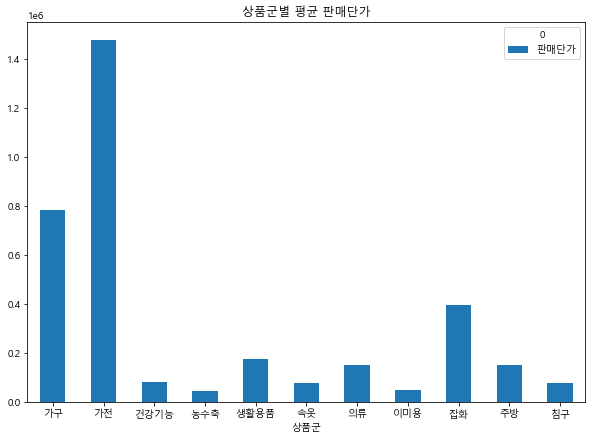
final.pivot_table(index='상품군', aggfunc='mean', values='판매단가').plot(kind='bar', rot=0)
plt.title('상품군별 평균 판매단가')
Text(0.5, 1.0, '상품군별 평균 판매단가')
temp = train.pivot_table(index='판매단가', aggfunc='mean', values='주문량').sort_values(by='주문량', ascending=False)
np.mean(temp.iloc[:129].index)
83329.8449612403
np.mean(temp.iloc[129:(129+129)].index)
791922.480620155
lst = []
for i in tqdm(range(train.shape[0])):
temp = train.iloc[i]['판매단가']
if temp <= 80000:
lst.append(1)
elif (temp >= 80000) & (temp < 800000):
lst.append(2)
else:
lst.append(3)
train['판매단가등급'] = lst
lst2 = []
for i in tqdm(range(test.shape[0])):
temp = test.iloc[i]['판매단가']
if temp <= 80000:
lst2.append(1)
elif (temp >= 80000) & (temp < 800000):
lst2.append(2)
else:
lst2.append(3)
test['판매단가등급'] = lst2
100%|██████████| 35379/35379 [00:06<00:00, 5198.03it/s]
100%|██████████| 2891/2891 [00:00<00:00, 5269.74it/s]
상품명을 기준으로 embedding 행렬 만들기
# 훈련 및 테스트 셋에서 상품명 컬럼만 뽑아서 데이터셋 만들기
train_product = train[['상품명']]
test_product = test[['상품명']]
data = pd.concat([train_product, test_product], axis = 0)
data = data.reset_index(drop = True)
data
| 상품명 | |
|---|---|
| 0 | 테이트 남성 셀린니트3종 |
| 1 | 테이트 여성 셀린니트3종 |
| 2 | 테이트 남성 셀린니트3종 |
| 3 | 테이트 여성 셀린니트3종 |
| 4 | 테이트 남성 셀린니트3종 |
| ... | ... |
| 38265 | 쉴렉스 안마의자 렌탈서비스 |
| 38266 | 쉴렉스 안마의자 렌탈서비스 |
| 38267 | 쉴렉스 안마의자 렌탈서비스 |
| 38268 | 아놀드파마 티셔츠레깅스세트 |
| 38269 | 아놀드파마 티셔츠레깅스세트 |
38270 rows × 1 columns
# 전체 상품명 데이터에서 한글만 남기기
for k in tqdm(range(len(data))):
# 한글만 남기기
hangul = re.compile('[^ㄱ-ㅣ가-힣]+')
data['상품명'][k] = hangul.sub(' ', data['상품명'][k])
100%|██████████| 38270/38270 [00:08<00:00, 4311.82it/s]
# 한글 상품명에서 명사만 추출하기
okt = Okt()
for k in tqdm(range(len(data))):
data['상품명'][k] = okt.nouns(data['상품명'][k])
100%|██████████| 41200/41200 [01:02<00:00, 656.20it/s]
data.head()
| 상품명 | |
|---|---|
| 0 | 테이트 남성 셀린니트 종 |
| 1 | 테이트 여성 셀린니트 종 |
| 2 | 테이트 남성 셀린니트 종 |
| 3 | 테이트 여성 셀린니트 종 |
| 4 | 테이트 남성 셀린니트 종 |
# 단어 집합 만들기
s = set()
for i in tqdm(range(data.shape[0])):
for j in data.iloc[i]['상품명']:
s.add(j)
100%|██████████| 38270/38270 [00:03<00:00, 9703.03it/s]
# 추출 된 명사가 컬럼으로 이루어진 희소행렬 생성
emb_df = pd.DataFrame(np.zeros((data.shape[0], len(s))), columns=list(s))
# 희소행렬 값 채우기
for i in tqdm(range(data.shape[0])):
for j in data.iloc[i]['상품명']:
emb_df.iloc[i][j] = 1
emb_df
100%|██████████| 38270/38270 [04:39<00:00, 137.14it/s]
| 팽 | 툴 | 슬 | 퀸 | 켄 | 혜 | 티 | 회 | 퀼 | 세 | 늄 | 스 | 들 | 염 | 맘 | 널 | 꼬 | 퀘 | 써 | 겹 | 녘 | 폼 | 연 | 퓨 | 펫 | 남 | 압 | 감 | 홑 | 목 | 샴 | 통 | 수 | 풀 | 꽃 | 후 | 루 | 멋 | 론 | 광 | ... | 유 | 텀 | 아 | 처 | 빈 | 따 | 운 | 롱 | 돼 | 톨 | 샐 | 택 | 틱 | 힐 | 낚 | 톡 | 산 | 애 | 붙 | 삼 | 쉘 | 탠 | 령 | 폐 | 흥 | 허 | 경 | 맛 | 셰 | 슈 | 링 | 급 | 샘 | 중 | 펙 | 뚜 | 쓰 | 배 | 양 | 깍 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 2 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 3 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 4 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 38265 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 38266 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 38267 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 38268 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 38269 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
38270 rows × 725 columns
emb_df.sum(axis=1)
0 10.00
1 10.00
2 10.00
3 10.00
4 10.00
...
38265 12.00
38266 12.00
38267 12.00
38268 14.00
38269 14.00
Length: 38270, dtype: float64
emb_df = pd.read_csv("/content/drive/Shared drives/빅콘테스트2020/data/2020빅콘테스트/01_제공데이터/emb_df.csv")
emb_df.drop(['Unnamed: 0'], axis=1, inplace=True)
emb_df
| 흥양 | 프린팅 | 시래기 | 홍어 | 안국루테 | 클렌 | 배터리 | 어스 | 캠프 | 신 | 컬럼비아 | 노 | 대자리 | 진액 | 양태 | 호빵 | 약 | 말랭이 | 클란츠 | 안마 | 젠트 | 큐 | 메모리 | 굴비 | 시어서커 | 이크 | 플랩 | 터틀넥 | 스팀 | 살롱 | 인버터 | 농원 | 꼬리곰탕 | 국수 | 분리 | 티슈 | 두 | 제옥스 | 순면 | 황사 | ... | 엑슬 | 레스 | 렌 | 아트 | 한장 | 간장 | 체증 | 킹스 | 쿠킹 | 히터 | 폼폼 | 미란다 | 싹 | 더탑 | 수련 | 캐시 | 가능 | 야생화 | 영광군 | 쇼케이스 | 숄더백 | 감성 | 깍두기 | 렌탈 | 풀 | 레깅스 | 링 | 단순 | 돌침대 | 로퍼 | 스파 | 로션 | 히트 | 베니스 | 하프 | 화장 | 퍼니쿡 | 모닝 | 캣 | 베드룸 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 2 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 3 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 4 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 38265 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 38266 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 38267 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 38268 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 38269 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ... | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
38270 rows × 2012 columns
# 행렬분해
svd_model = TruncatedSVD(n_components=160, algorithm='randomized', n_iter=50, random_state=321)
svd_model.fit(emb_df.T)
TruncatedSVD(algorithm='randomized', n_components=160, n_iter=50,
random_state=321, tol=0.0)
temp = pd.DataFrame(svd_model.components_.T)
# 임베딩 행렬 스케일링 진행 (RobustScaler)
from sklearn.preprocessing import MinMaxScaler, RobustScaler
scaler = RobustScaler()
scaler.fit(temp)
temp = pd.DataFrame(scaler.transform(temp), columns=temp.columns)
# 임베딩 행렬 K-means clustering (대분류 : 13개, 중분류 : 67개, 소분류 : 100개)
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters= 13, random_state=510, max_iter=100).fit(temp.iloc[: , :160])
temp['emb_label'] = kmeans.labels_
kmeans2 = KMeans(n_clusters= 67, random_state=510, max_iter=100).fit(temp.iloc[: , :160])
temp['emb_label2'] = kmeans2.labels_
kmeans3 = KMeans(n_clusters= 100, random_state=510, max_iter=100).fit(temp.iloc[: , :160])
temp['emb_label3'] = kmeans3.labels_
train = pd.concat([train, temp.iloc[:35379]], axis=1)
test = pd.concat([test.reset_index().drop(['index'], axis=1), temp.iloc[35379:].reset_index().drop(['index'], axis=1)], axis=1)
# 훈련, 시험셋의 '방송일시'변수 datetime으로 변경 후 '월','일' 변수 생성
train['방송일시'] = pd.to_datetime(train['방송일시'])
test['방송일시'] = pd.to_datetime(test['방송일시'])
train['월'] = train['방송일시'].dt.month
train['일'] = train['방송일시'].dt.day
test['월'] = test['방송일시'].dt.month
test['일'] = test['방송일시'].dt.day
train / test split
* train data안에서의 주문량만 학습하기 위해 미리 분리
train_train, train_test = [], []
np.random.seed(510)
idx = np.random.choice(train.shape[0], size=round(train.shape[0] * 0.8), replace=False)
for i in tqdm(range(train.shape[0])):
if i in idx:
train_train.append(i)
else:
train_test.append(i)
print('train_train :', len(train_train))
print('train_test :', len(train_test))
100%|██████████| 35379/35379 [00:00<00:00, 65757.33it/s]
train_train : 28303
train_test : 7076
train_data = train.iloc[train_train,:]
test_data = train.iloc[train_test,:]
print(train_data.shape)
print(test_data.shape)
(28303, 182)
(7076, 182)
주문량에따른 시간대별 등급
temp = train.pivot_table(index=['시'], aggfunc='mean', values='주문량').sort_values(by='주문량', ascending=False)
dic = {'1':temp.index[:5].tolist(),
'2':temp.index[5:(5+5)].tolist(),
'3':temp.index[(5+5):(5+5+6)].tolist(),
'4':temp.index[(5+5+6):].tolist()}
print('전체 train \n')
lst = []
for i in tqdm(range(train.shape[0])):
temp2 = train.iloc[i]['시']
if temp2 in dic['1']:
lst.append(0)
elif temp2 in dic['2']:
lst.append(1)
elif temp2 in dic['3']:
lst.append(2)
else:
lst.append(3)
train['시등급'] = lst
2%|▏ | 590/35379 [00:00<00:12, 2876.60it/s]
전체 train
100%|██████████| 35379/35379 [00:11<00:00, 3045.25it/s]
temp = train_data.pivot_table(index=['시'], aggfunc='mean', values='주문량').sort_values(by='주문량', ascending=False)
dic = {'1':temp.index[:5].tolist(),
'2':temp.index[5:(5+5)].tolist(),
'3':temp.index[(5+5):(5+5+6)].tolist(),
'4':temp.index[(5+5+6):].tolist()}
print('학습 data 중 train \n')
lst = []
for i in tqdm(range(train_data.shape[0])):
temp2 = train_data.iloc[i]['시']
if temp2 in dic['1']:
lst.append(0)
elif temp2 in dic['2']:
lst.append(1)
elif temp2 in dic['3']:
lst.append(2)
else:
lst.append(3)
train_data['시등급'] = lst
print('학습 data 중 test \n')
lst2 = []
for i in tqdm(range(test_data.shape[0])):
temp2 = test_data.iloc[i]['시']
if temp2 in dic['1']:
lst2.append(0)
elif temp2 in dic['2']:
lst2.append(1)
elif temp2 in dic['3']:
lst2.append(2)
else:
lst2.append(3)
test_data['시등급'] = lst2
print('평가 data \n')
lst3 = []
for i in tqdm(range(test.shape[0])):
temp2 = test.iloc[i]['시']
if temp2 in dic['1']:
lst3.append(0)
elif temp2 in dic['2']:
lst3.append(1)
elif temp2 in dic['3']:
lst3.append(2)
elif temp2 in dic['4']:
lst3.append(3)
else:
lst3.append(np.nan)
test['시등급'] = lst3
2%|▏ | 624/28303 [00:00<00:08, 3080.29it/s]
학습 data 중 train
100%|██████████| 28303/28303 [00:09<00:00, 3099.82it/s]
/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:23: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
9%|▉ | 621/7076 [00:00<00:02, 3015.26it/s]
학습 data 중 test
100%|██████████| 7076/7076 [00:02<00:00, 3064.61it/s]
/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:39: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
21%|██▏ | 617/2891 [00:00<00:00, 3113.08it/s]
평가 data
100%|██████████| 2891/2891 [00:00<00:00, 3032.51it/s]
test.head(1)
| 방송일시 | 노출(분) | 마더코드 | 상품코드 | 상품명 | 상품군 | 판매단가 | 취급액 | 날짜 | 시 | 분 | 요일 | 휴일 | season | 노출횟수 | 판매단가등급 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | ... | 131 | 132 | 133 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | 153 | 154 | 155 | 156 | 157 | 158 | 159 | emb_label | emb_label2 | emb_label3 | 월 | 일 | 시등급 | 분등급 | emb_label_주문량 | emb_label2_주문량 | emb_label3_주문량 | 월_주문량 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2020-06-01 06:20:00 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | 59800 | NaN | 2020-06-01 | 6 | 20 | 1 | 0 | 1 | 1 | 1 | -0.04 | 2.42 | -1.72 | -0.56 | -1.86 | -0.09 | -2.14 | -0.58 | -0.61 | 3.23 | -0.29 | 0.11 | -0.29 | -0.47 | 0.44 | -0.56 | 0.24 | 1.54 | -1.12 | -0.68 | 1.24 | -1.39 | -1.66 | 2.01 | ... | -0.93 | -0.71 | -0.62 | -0.13 | 0.25 | -0.66 | -0.30 | -0.36 | 0.69 | 0.93 | 0.63 | -0.46 | -0.38 | 0.94 | -0.98 | 0.54 | -0.43 | 0.30 | -1.25 | 1.34 | -0.52 | 0.64 | -1.54 | 0.68 | -1.14 | 0.66 | 0.28 | -0.24 | -1.21 | 2 | 83 | 83 | 6 | 1 | 2 | 0 | 300.74 | 416.68 | 416.68 | 305.60 |
1 rows × 187 columns
temp = train.pivot_table(index=['분'], aggfunc='mean', values='주문량').sort_values(by='주문량', ascending=False)
dic = {'1':temp.index[:3].tolist(),
'2':temp.index[3:(3+4)].tolist(),
'3':temp.index[(3+4):].tolist()}
print('전체 train \n')
lst = []
for i in tqdm(range(train.shape[0])):
temp2 = train.iloc[i]['분']
if temp2 in dic['1']:
lst.append(0)
elif temp2 in dic['2']:
lst.append(1)
elif temp2 in dic['3']:
lst.append(2)
else:
lst.append(3)
train['분등급'] = lst
2%|▏ | 632/35379 [00:00<00:10, 3161.42it/s]
전체 train
100%|██████████| 35379/35379 [00:11<00:00, 3104.19it/s]
temp = train_data.pivot_table(index=['분'], aggfunc='mean', values='주문량').sort_values(by='주문량', ascending=False)
dic = {'1':temp.index[:3].tolist(),
'2':temp.index[3:(3+4)].tolist(),
'3':temp.index[(3+4):].tolist()}
print('학습 data 중 train \n')
lst = []
for i in tqdm(range(train_data.shape[0])):
temp2 = train_data.iloc[i]['분']
if temp2 in dic['1']:
lst.append(0)
elif temp2 in dic['2']:
lst.append(1)
else:
lst.append(2)
train_data['분등급'] = lst
print('학습 data 중 test \n')
lst2 = []
for i in tqdm(range(test_data.shape[0])):
temp2 = test_data.iloc[i]['분']
if temp2 in dic['1']:
lst2.append(0)
elif temp2 in dic['2']:
lst2.append(1)
else:
lst2.append(2)
test_data['분등급'] = lst2
print('평가 data \n')
lst3 = []
for i in tqdm(range(test.shape[0])):
temp2 = test.iloc[i]['분']
if temp2 in dic['1']:
lst3.append(0)
elif temp2 in dic['2']:
lst3.append(1)
elif temp2 in dic['3']:
lst3.append(2)
else:
lst3.append(np.nan)
test['분등급'] = lst3
2%|▏ | 660/28303 [00:00<00:08, 3344.74it/s]
학습 data 중 train
100%|██████████| 28303/28303 [00:09<00:00, 3095.95it/s]
/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:20: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
18%|█▊ | 1246/7076 [00:00<00:01, 3087.44it/s]
학습 data 중 test
100%|██████████| 7076/7076 [00:02<00:00, 3066.61it/s]
/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:35: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
51%|█████▏ | 1482/2891 [00:00<00:00, 2983.40it/s]
평가 data
100%|██████████| 2891/2891 [00:00<00:00, 3008.91it/s]
평균 주문량 column 생성
train_data.pivot_table(index='emb_label', aggfunc='mean', values='주문량').sort_values(by='주문량', ascending=False).reset_index()
| emb_label | 주문량 | |
|---|---|---|
| 0 | 10 | 1492.11 |
| 1 | 5 | 1022.19 |
| 2 | 4 | 1007.99 |
| 3 | 6 | 877.25 |
| 4 | 8 | 862.38 |
| 5 | 7 | 810.78 |
| 6 | 11 | 810.28 |
| 7 | 1 | 755.63 |
| 8 | 3 | 542.33 |
| 9 | 9 | 423.78 |
| 10 | 2 | 302.53 |
| 11 | 0 | 78.35 |
| 12 | 12 | 69.18 |
# train_data
lst = ['emb_label', 'emb_label2', 'emb_label3', '월', '시등급', '분등급', '요일','노출횟수']
for i in lst:
temp = train_data.pivot_table(index=i, aggfunc='mean', values='주문량').sort_values(by='주문량', ascending=False).reset_index()
temp.columns= [i, str(i)+'_주문량']
train_data = pd.merge(train_data, temp, how='left', on=i)
# test_data
lst = ['emb_label', 'emb_label2', 'emb_label3', '월', '시등급', '분등급', '요일','노출횟수']
for i in lst:
temp = train_data.pivot_table(index=i, aggfunc='mean', values='주문량').sort_values(by='주문량', ascending=False).reset_index()
temp.columns= [i, str(i)+'_주문량']
test_data = pd.merge(test_data, temp, how='left', on=i)
# test
lst = ['emb_label', 'emb_label2', 'emb_label3', '월', '시등급', '분등급', '요일','노출횟수']
for i in lst:
# test에서는 전체 train으로 학습
temp = train.pivot_table(index=i, aggfunc='mean', values='주문량').sort_values(by='주문량', ascending=False).reset_index()
temp.columns= [i, str(i)+'_주문량']
test = pd.merge(test, temp, how='left', on=i)
print(train_data.shape)
print(test_data.shape)
print(test.shape)
(28303, 193)
(7076, 193)
(2891, 192)
원하는 column 선택
col = ['emb_label_주문량', 'emb_label2_주문량', 'emb_label3_주문량', '월_주문량', '요일_주문량', '시등급_주문량', '분등급_주문량','노출횟수_주문량', '판매단가']
Robust Scaling
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
scaler.fit(train_data[col])
train_data[col] = pd.DataFrame(scaler.transform(train_data[col]), columns=train_data[col].columns)
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
scaler.fit(test_data[col])
test_data[col] = pd.DataFrame(scaler.transform(test_data[col]), columns=test_data[col].columns)
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
scaler.fit(test[col])
test[col] = pd.DataFrame(scaler.transform(test[col]), columns=test[col].columns)
col.extend([x for x in range(159)])
len(col)
168
비어있는 값 평균으로 대체
# 평균값으로 대체
for i in col:
test_data[i].fillna(test_data[i].mean(), inplace=True)
독립변수, 종속변수 분리
X_train = train_data[col]
y_train = train_data['주문량']
X_test = test_data[col]
y_test = test_data['주문량']
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
(28303, 168)
(28303,)
(7076, 168)
(7076,)
X_train = X_train.values
y_train = y_train.values
X_test = X_test.values
y_test = y_test.values
모델링
from keras.layers import Dense, Activation, Flatten, Conv1D, MaxPooling1D, AveragePooling1D, GlobalAveragePooling1D, Conv1DTranspose, concatenate, Input, add, Dropout, BatchNormalization
from tensorflow.keras import Model
def build_model(input_layer, start_neurons):
conv1 = Conv1D(start_neurons * 1, 3, activation="elu", padding="same", kernel_initializer='he_normal', input_shape=(X_train.shape[1], 1))(input_layer)
conv1 = Conv1D(start_neurons * 1, 3, activation="elu", padding="same", kernel_initializer='he_normal')(conv1)
pool1 = BatchNormalization()(conv1)
pool1 = MaxPooling1D(2)(pool1)
pool1 = Dropout(0.3)(pool1)
conv2 = Conv1D(start_neurons * 2, 3, activation="elu", padding="same", kernel_initializer='he_normal')(pool1)
conv2 = Conv1D(start_neurons * 2, 3, activation="elu", padding="same", kernel_initializer='he_normal')(conv2)
pool2 = BatchNormalization()(conv2)
pool2 = MaxPooling1D(2)(pool2)
pool2 = Dropout(0.3)(pool2)
conv3 = Conv1D(start_neurons * 2, 3, activation="elu", padding="same", kernel_initializer='he_normal')(pool2)
conv3 = Conv1D(start_neurons * 2, 3, activation="elu", padding="same", kernel_initializer='he_normal')(conv3)
pool3 = BatchNormalization()(conv3)
pool3 = AveragePooling1D(2)(pool3)
pool3 = Dropout(0.3)(pool3)
convm = Conv1D(start_neurons * 4, 3, activation="elu", padding="same",kernel_initializer='he_normal')(pool3)
deconv3 = Conv1DTranspose(start_neurons * 1, 3, strides=2, padding="same",kernel_initializer='he_normal')(convm)
uconv3 = concatenate([deconv3, conv3])
uconv3 = Dropout(0.15)(uconv3)
uconv3 = Conv1D(start_neurons * 1, 3, activation="elu", padding="same",kernel_initializer='he_normal')(uconv3)
uconv3 = Conv1D(start_neurons * 1, 3, activation="elu", padding="same",kernel_initializer='he_normal')(uconv3)
uconv3 = BatchNormalization()(uconv3)
uconv3 = Dropout(0.3)(uconv3)
deconv2 = Conv1DTranspose(start_neurons * 1, 3, strides=2, padding="same",kernel_initializer='he_normal')(uconv3)
uconv2 = concatenate([deconv2, conv2])
uconv2 = Dropout(0.3)(uconv2)
uconv2 = Conv1D(start_neurons * 1, 3, activation="elu", padding="same",kernel_initializer='he_normal')(uconv2)
uconv2 = Conv1D(start_neurons * 1, 3, activation="elu", padding="same",kernel_initializer='he_normal')(uconv2)
uconv2 = BatchNormalization()(uconv2)
uconv2 = Dropout(0.3)(uconv2)
deconv1 = Conv1DTranspose(start_neurons * 1, 3, strides=2, padding="same",kernel_initializer='he_normal')(uconv2)
uconv1 = concatenate([deconv1, conv1])
uconv1 = Dropout(0.3)(uconv1)
uconv1 = Conv1D(start_neurons * 1, 3, activation="elu", padding="same",kernel_initializer='he_normal')(uconv1)
uconv1 = Conv1D(start_neurons * 1, 3, activation="elu", padding="same",kernel_initializer='he_normal')(uconv1)
uconv1 = BatchNormalization()(uconv1)
uconv1 = Dropout(0.3)(uconv1)
flat = Flatten()(uconv1)
dense1 = Dense(256, activation='elu')(flat)
dense2 = Dense(128, activation='elu')(dense1)
output_layer = Dense(1)(dense2)
return output_layer
input_layer = Input((X_train.shape[1], 1))
output_layer = build_model(input_layer, 128)
model = Model(input_layer, output_layer)
model.summary()
Model: "functional_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 168, 1)] 0
__________________________________________________________________________________________________
conv1d (Conv1D) (None, 168, 128) 512 input_1[0][0]
__________________________________________________________________________________________________
conv1d_1 (Conv1D) (None, 168, 128) 49280 conv1d[0][0]
__________________________________________________________________________________________________
batch_normalization (BatchNorma (None, 168, 128) 512 conv1d_1[0][0]
__________________________________________________________________________________________________
max_pooling1d (MaxPooling1D) (None, 84, 128) 0 batch_normalization[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 84, 128) 0 max_pooling1d[0][0]
__________________________________________________________________________________________________
conv1d_2 (Conv1D) (None, 84, 256) 98560 dropout[0][0]
__________________________________________________________________________________________________
conv1d_3 (Conv1D) (None, 84, 256) 196864 conv1d_2[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 84, 256) 1024 conv1d_3[0][0]
__________________________________________________________________________________________________
max_pooling1d_1 (MaxPooling1D) (None, 42, 256) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 42, 256) 0 max_pooling1d_1[0][0]
__________________________________________________________________________________________________
conv1d_4 (Conv1D) (None, 42, 256) 196864 dropout_1[0][0]
__________________________________________________________________________________________________
conv1d_5 (Conv1D) (None, 42, 256) 196864 conv1d_4[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 42, 256) 1024 conv1d_5[0][0]
__________________________________________________________________________________________________
average_pooling1d (AveragePooli (None, 21, 256) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, 21, 256) 0 average_pooling1d[0][0]
__________________________________________________________________________________________________
conv1d_6 (Conv1D) (None, 21, 512) 393728 dropout_2[0][0]
__________________________________________________________________________________________________
conv1d_transpose (Conv1DTranspo (None, 42, 128) 196736 conv1d_6[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 42, 384) 0 conv1d_transpose[0][0]
conv1d_5[0][0]
__________________________________________________________________________________________________
dropout_3 (Dropout) (None, 42, 384) 0 concatenate[0][0]
__________________________________________________________________________________________________
conv1d_7 (Conv1D) (None, 42, 128) 147584 dropout_3[0][0]
__________________________________________________________________________________________________
conv1d_8 (Conv1D) (None, 42, 128) 49280 conv1d_7[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 42, 128) 512 conv1d_8[0][0]
__________________________________________________________________________________________________
dropout_4 (Dropout) (None, 42, 128) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
conv1d_transpose_1 (Conv1DTrans (None, 84, 128) 49280 dropout_4[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 84, 384) 0 conv1d_transpose_1[0][0]
conv1d_3[0][0]
__________________________________________________________________________________________________
dropout_5 (Dropout) (None, 84, 384) 0 concatenate_1[0][0]
__________________________________________________________________________________________________
conv1d_9 (Conv1D) (None, 84, 128) 147584 dropout_5[0][0]
__________________________________________________________________________________________________
conv1d_10 (Conv1D) (None, 84, 128) 49280 conv1d_9[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 84, 128) 512 conv1d_10[0][0]
__________________________________________________________________________________________________
dropout_6 (Dropout) (None, 84, 128) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
conv1d_transpose_2 (Conv1DTrans (None, 168, 128) 49280 dropout_6[0][0]
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 168, 256) 0 conv1d_transpose_2[0][0]
conv1d_1[0][0]
__________________________________________________________________________________________________
dropout_7 (Dropout) (None, 168, 256) 0 concatenate_2[0][0]
__________________________________________________________________________________________________
conv1d_11 (Conv1D) (None, 168, 128) 98432 dropout_7[0][0]
__________________________________________________________________________________________________
conv1d_12 (Conv1D) (None, 168, 128) 49280 conv1d_11[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 168, 128) 512 conv1d_12[0][0]
__________________________________________________________________________________________________
dropout_8 (Dropout) (None, 168, 128) 0 batch_normalization_5[0][0]
__________________________________________________________________________________________________
flatten (Flatten) (None, 21504) 0 dropout_8[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 256) 5505280 flatten[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 128) 32896 dense[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 1) 129 dense_1[0][0]
==================================================================================================
Total params: 7,511,809
Trainable params: 7,509,761
Non-trainable params: 2,048
__________________________________________________________________________________________________
from keras.callbacks import ModelCheckpoint
from keras import optimizers
import keras.backend as K
adam = optimizers.Adam(lr=0.0002, beta_1=0.5, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
def mape(y_true, y_pred):
return K.mean(K.abs((y_pred - y_true) / y_true), axis=-1) * 100
def compile_and_train(model, num_epochs):
model.compile(optimizer=adam,
loss=mape,
metrics=['mean_squared_error'])
filepath = 'drive/Shared drives/빅콘테스트2020/weights/ds/' + model.name + '.{epoch:02d}-{val_loss:.4f}.hdf5'
checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_weights_only=True, save_best_only=True, mode='auto')
model_history = model.fit(X_train, y_train, epochs=num_epochs, verbose=1, callbacks=[checkpoint], validation_data=(X_test, y_test), batch_size = 32)
return model.history
_=compile_and_train(model, num_epochs = 50)
Epoch 1/50
885/885 [==============================] - 15s 17ms/step - loss: 72.0506 - mean_squared_error: 234444.2031 - val_loss: 61.1960 - val_mean_squared_error: 190769.1875
Epoch 2/50
885/885 [==============================] - 12s 13ms/step - loss: 54.1626 - mean_squared_error: 135448.0625 - val_loss: 49.1079 - val_mean_squared_error: 100337.9141
Epoch 3/50
885/885 [==============================] - 11s 13ms/step - loss: 47.3490 - mean_squared_error: 94437.4453 - val_loss: 45.5351 - val_mean_squared_error: 79575.7578
Epoch 4/50
885/885 [==============================] - 12s 13ms/step - loss: 44.0135 - mean_squared_error: 79859.2656 - val_loss: 43.8869 - val_mean_squared_error: 68972.0781
Epoch 5/50
885/885 [==============================] - 11s 13ms/step - loss: 42.0960 - mean_squared_error: 71360.8359 - val_loss: 41.7467 - val_mean_squared_error: 66719.9375
Epoch 6/50
885/885 [==============================] - 11s 13ms/step - loss: 41.1415 - mean_squared_error: 67721.0156 - val_loss: 41.3399 - val_mean_squared_error: 58520.4336
Epoch 7/50
885/885 [==============================] - 11s 13ms/step - loss: 40.1173 - mean_squared_error: 64727.7852 - val_loss: 40.2029 - val_mean_squared_error: 56525.2500
Epoch 8/50
885/885 [==============================] - 11s 13ms/step - loss: 39.1574 - mean_squared_error: 61619.9492 - val_loss: 39.9463 - val_mean_squared_error: 52776.7656
Epoch 9/50
885/885 [==============================] - 11s 13ms/step - loss: 38.4144 - mean_squared_error: 59078.5977 - val_loss: 39.8683 - val_mean_squared_error: 53505.7383
Epoch 10/50
885/885 [==============================] - 11s 13ms/step - loss: 37.8804 - mean_squared_error: 57405.5273 - val_loss: 38.9853 - val_mean_squared_error: 48913.6523
Epoch 11/50
885/885 [==============================] - 11s 13ms/step - loss: 37.2552 - mean_squared_error: 56105.9414 - val_loss: 39.4120 - val_mean_squared_error: 48378.4062
Epoch 12/50
885/885 [==============================] - 11s 13ms/step - loss: 36.7965 - mean_squared_error: 54459.7109 - val_loss: 38.2957 - val_mean_squared_error: 52089.9375
Epoch 13/50
885/885 [==============================] - 11s 13ms/step - loss: 36.2845 - mean_squared_error: 52827.2578 - val_loss: 40.1860 - val_mean_squared_error: 50487.9414
Epoch 14/50
885/885 [==============================] - 11s 13ms/step - loss: 35.8560 - mean_squared_error: 51796.0898 - val_loss: 38.3331 - val_mean_squared_error: 51249.4102
Epoch 15/50
885/885 [==============================] - 11s 13ms/step - loss: 35.3632 - mean_squared_error: 51349.4727 - val_loss: 37.7870 - val_mean_squared_error: 49001.3984
Epoch 16/50
885/885 [==============================] - 11s 13ms/step - loss: 35.0045 - mean_squared_error: 49887.8164 - val_loss: 37.4562 - val_mean_squared_error: 44092.1875
Epoch 17/50
885/885 [==============================] - 11s 12ms/step - loss: 34.6247 - mean_squared_error: 48738.2031 - val_loss: 38.2878 - val_mean_squared_error: 41336.3516
Epoch 18/50
885/885 [==============================] - 11s 13ms/step - loss: 34.1496 - mean_squared_error: 47793.4805 - val_loss: 37.1594 - val_mean_squared_error: 45582.0234
Epoch 19/50
885/885 [==============================] - 11s 12ms/step - loss: 33.9325 - mean_squared_error: 46562.1328 - val_loss: 37.9922 - val_mean_squared_error: 41560.4531
Epoch 20/50
885/885 [==============================] - 12s 13ms/step - loss: 33.5639 - mean_squared_error: 47068.8789 - val_loss: 37.0304 - val_mean_squared_error: 43149.8711
Epoch 21/50
885/885 [==============================] - 11s 12ms/step - loss: 33.3884 - mean_squared_error: 46241.5781 - val_loss: 37.5516 - val_mean_squared_error: 43254.2461
Epoch 22/50
885/885 [==============================] - 11s 13ms/step - loss: 33.1104 - mean_squared_error: 45609.0898 - val_loss: 36.7937 - val_mean_squared_error: 44383.8516
Epoch 23/50
885/885 [==============================] - 11s 13ms/step - loss: 32.6400 - mean_squared_error: 44881.6992 - val_loss: 36.8421 - val_mean_squared_error: 41828.2227
Epoch 24/50
885/885 [==============================] - 12s 14ms/step - loss: 32.4107 - mean_squared_error: 43639.3789 - val_loss: 37.6604 - val_mean_squared_error: 40397.3789
Epoch 25/50
885/885 [==============================] - 12s 13ms/step - loss: 32.2566 - mean_squared_error: 43842.2109 - val_loss: 36.4007 - val_mean_squared_error: 40288.7461
Epoch 26/50
885/885 [==============================] - 11s 13ms/step - loss: 32.0389 - mean_squared_error: 43110.4766 - val_loss: 36.6331 - val_mean_squared_error: 41046.0234
Epoch 27/50
885/885 [==============================] - 11s 13ms/step - loss: 31.8357 - mean_squared_error: 42669.5742 - val_loss: 36.7838 - val_mean_squared_error: 43534.1133
Epoch 28/50
885/885 [==============================] - 11s 13ms/step - loss: 31.5333 - mean_squared_error: 42252.8633 - val_loss: 36.4919 - val_mean_squared_error: 38932.3750
Epoch 29/50
885/885 [==============================] - 11s 13ms/step - loss: 31.2561 - mean_squared_error: 41602.4922 - val_loss: 36.4576 - val_mean_squared_error: 41832.2969
Epoch 30/50
885/885 [==============================] - 11s 13ms/step - loss: 31.0332 - mean_squared_error: 41261.7852 - val_loss: 36.6560 - val_mean_squared_error: 38453.8750
Epoch 31/50
885/885 [==============================] - 11s 13ms/step - loss: 30.7985 - mean_squared_error: 41094.7539 - val_loss: 36.8772 - val_mean_squared_error: 37594.9336
Epoch 32/50
885/885 [==============================] - 11s 13ms/step - loss: 30.6786 - mean_squared_error: 40779.6016 - val_loss: 37.0396 - val_mean_squared_error: 38687.1172
Epoch 33/50
885/885 [==============================] - 11s 13ms/step - loss: 30.4793 - mean_squared_error: 40117.2695 - val_loss: 36.4555 - val_mean_squared_error: 38903.3047
Epoch 34/50
885/885 [==============================] - 12s 13ms/step - loss: 30.2910 - mean_squared_error: 40149.5078 - val_loss: 36.7116 - val_mean_squared_error: 38447.3633
Epoch 35/50
885/885 [==============================] - 11s 13ms/step - loss: 30.0343 - mean_squared_error: 39446.6641 - val_loss: 37.0447 - val_mean_squared_error: 36690.2109
Epoch 36/50
885/885 [==============================] - 11s 13ms/step - loss: 29.8964 - mean_squared_error: 39361.0469 - val_loss: 36.9854 - val_mean_squared_error: 34572.7852
Epoch 37/50
885/885 [==============================] - 11s 12ms/step - loss: 29.8083 - mean_squared_error: 38438.1875 - val_loss: 37.4272 - val_mean_squared_error: 38197.5430
Epoch 38/50
885/885 [==============================] - 11s 13ms/step - loss: 29.5378 - mean_squared_error: 38513.3203 - val_loss: 36.8323 - val_mean_squared_error: 37720.9453
Epoch 39/50
885/885 [==============================] - 11s 13ms/step - loss: 29.4717 - mean_squared_error: 37744.6367 - val_loss: 37.7488 - val_mean_squared_error: 35258.0273
Epoch 40/50
885/885 [==============================] - 12s 13ms/step - loss: 29.1888 - mean_squared_error: 37239.0156 - val_loss: 36.9798 - val_mean_squared_error: 36627.8477
Epoch 41/50
885/885 [==============================] - 12s 13ms/step - loss: 28.9853 - mean_squared_error: 37188.5273 - val_loss: 36.7871 - val_mean_squared_error: 37009.3984
Epoch 42/50
885/885 [==============================] - 12s 13ms/step - loss: 28.7947 - mean_squared_error: 36458.3516 - val_loss: 36.2778 - val_mean_squared_error: 36043.4922
Epoch 43/50
885/885 [==============================] - 12s 13ms/step - loss: 28.7667 - mean_squared_error: 36105.4961 - val_loss: 36.0185 - val_mean_squared_error: 36986.2148
Epoch 44/50
885/885 [==============================] - 11s 13ms/step - loss: 28.5003 - mean_squared_error: 36118.9648 - val_loss: 37.2940 - val_mean_squared_error: 41636.2773
Epoch 45/50
885/885 [==============================] - 11s 13ms/step - loss: 28.3166 - mean_squared_error: 35577.6602 - val_loss: 36.6263 - val_mean_squared_error: 34687.6289
Epoch 46/50
885/885 [==============================] - 11s 13ms/step - loss: 28.3254 - mean_squared_error: 35129.7461 - val_loss: 36.9247 - val_mean_squared_error: 36397.6758
Epoch 47/50
885/885 [==============================] - 11s 13ms/step - loss: 28.1238 - mean_squared_error: 35144.0234 - val_loss: 37.2090 - val_mean_squared_error: 33549.1289
Epoch 48/50
885/885 [==============================] - 11s 13ms/step - loss: 28.0206 - mean_squared_error: 34771.5195 - val_loss: 37.0418 - val_mean_squared_error: 33304.5273
Epoch 49/50
885/885 [==============================] - 11s 13ms/step - loss: 27.7911 - mean_squared_error: 34031.4844 - val_loss: 37.1774 - val_mean_squared_error: 32926.2109
Epoch 50/50
885/885 [==============================] - 11s 12ms/step - loss: 27.6829 - mean_squared_error: 34390.3984 - val_loss: 37.1884 - val_mean_squared_error: 32546.9590
test 취급액 예측
test.head()
| 방송일시 | 노출(분) | 마더코드 | 상품코드 | 상품명 | 상품군 | 판매단가 | 취급액 | 날짜 | 시 | 분 | 요일 | 휴일 | season | 노출횟수 | 판매단가등급 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | ... | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | 153 | 154 | 155 | 156 | 157 | 158 | 159 | emb_label | emb_label2 | emb_label3 | 월 | 일 | 시등급 | 분등급 | emb_label_주문량 | emb_label2_주문량 | emb_label3_주문량 | 월_주문량 | 시등급_주문량 | 분등급_주문량 | 요일_주문량 | 노출횟수_주문량 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2020-06-01 06:20:00 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | -0.04 | NaN | 2020-06-01 | 6 | 20 | 1 | 0 | 1 | 1 | 1 | -0.04 | 2.42 | -1.72 | -0.56 | -1.86 | -0.09 | -2.14 | -0.58 | -0.61 | 3.23 | -0.29 | 0.11 | -0.29 | -0.47 | 0.44 | -0.56 | 0.24 | 1.54 | -1.12 | -0.68 | 1.24 | -1.39 | -1.66 | 2.01 | ... | 0.25 | -0.66 | -0.30 | -0.36 | 0.69 | 0.93 | 0.63 | -0.46 | -0.38 | 0.94 | -0.98 | 0.54 | -0.43 | 0.30 | -1.25 | 1.34 | -0.52 | 0.64 | -1.54 | 0.68 | -1.14 | 0.66 | 0.28 | -0.24 | -1.21 | 2 | 83 | 83 | 6 | 1 | 2 | 0 | 0.00 | 0.06 | 0.06 | 0.00 | 0.00 | 0.00 | 0.00 | -0.54 |
| 1 | 2020-06-01 06:40:00 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | -0.04 | NaN | 2020-06-01 | 6 | 40 | 1 | 0 | 1 | 2 | 1 | -0.04 | 2.42 | -1.72 | -0.56 | -1.86 | -0.09 | -2.14 | -0.58 | -0.61 | 3.23 | -0.29 | 0.11 | -0.29 | -0.47 | 0.44 | -0.56 | 0.24 | 1.54 | -1.12 | -0.68 | 1.24 | -1.39 | -1.66 | 2.01 | ... | 0.25 | -0.66 | -0.30 | -0.36 | 0.69 | 0.93 | 0.63 | -0.46 | -0.38 | 0.94 | -0.98 | 0.54 | -0.43 | 0.30 | -1.25 | 1.34 | -0.52 | 0.64 | -1.54 | 0.68 | -1.14 | 0.66 | 0.28 | -0.24 | -1.21 | 2 | 83 | 83 | 6 | 1 | 2 | 0 | 0.00 | 0.06 | 0.06 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 2 | 2020-06-01 07:00:00 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | -0.04 | NaN | 2020-06-01 | 7 | 0 | 1 | 0 | 1 | 3 | 1 | -0.04 | 2.42 | -1.72 | -0.56 | -1.86 | -0.09 | -2.14 | -0.58 | -0.61 | 3.23 | -0.29 | 0.11 | -0.29 | -0.47 | 0.44 | -0.56 | 0.24 | 1.54 | -1.12 | -0.68 | 1.24 | -1.39 | -1.66 | 2.01 | ... | 0.25 | -0.66 | -0.30 | -0.36 | 0.69 | 0.93 | 0.63 | -0.46 | -0.38 | 0.94 | -0.98 | 0.54 | -0.43 | 0.30 | -1.25 | 1.34 | -0.52 | 0.64 | -1.54 | 0.68 | -1.14 | 0.66 | 0.28 | -0.24 | -1.21 | 2 | 83 | 83 | 6 | 1 | 1 | 1 | 0.00 | 0.06 | 0.06 | 0.00 | 0.38 | -1.00 | 0.00 | 0.46 |
| 3 | 2020-06-01 07:20:00 | 20 | 100445 | 202278 | 쿠미투니카 쿨 레이시 란쥬쉐이퍼&팬티 | 속옷 | -0.02 | NaN | 2020-06-01 | 7 | 20 | 1 | 0 | 1 | 1 | 1 | 0.14 | 0.19 | -0.03 | 3.75 | 0.34 | -0.61 | -0.34 | 2.96 | -0.83 | -1.10 | 0.43 | 0.12 | 0.87 | 0.65 | 0.52 | 0.16 | -2.10 | -2.93 | 1.02 | 3.78 | 2.22 | 2.51 | -1.18 | 6.25 | ... | -0.62 | 2.32 | 0.25 | 1.94 | 3.35 | -1.84 | -1.94 | 1.55 | 2.49 | 0.84 | -1.02 | -0.12 | 1.81 | -3.09 | 1.88 | 2.00 | 2.28 | 2.64 | 3.29 | -3.85 | -3.58 | 2.44 | 0.58 | -0.69 | -3.07 | 2 | 49 | 49 | 6 | 1 | 1 | 0 | 0.00 | 0.49 | 0.49 | 0.00 | 0.38 | 0.00 | 0.00 | -0.54 |
| 4 | 2020-06-01 07:40:00 | 20 | 100445 | 202278 | 쿠미투니카 쿨 레이시 란쥬쉐이퍼&팬티 | 속옷 | -0.02 | NaN | 2020-06-01 | 7 | 40 | 1 | 0 | 1 | 2 | 1 | 0.14 | 0.19 | -0.03 | 3.75 | 0.34 | -0.61 | -0.34 | 2.96 | -0.83 | -1.10 | 0.43 | 0.12 | 0.87 | 0.65 | 0.52 | 0.16 | -2.10 | -2.93 | 1.02 | 3.78 | 2.22 | 2.51 | -1.18 | 6.25 | ... | -0.62 | 2.32 | 0.25 | 1.94 | 3.35 | -1.84 | -1.94 | 1.55 | 2.49 | 0.84 | -1.02 | -0.12 | 1.81 | -3.09 | 1.88 | 2.00 | 2.28 | 2.64 | 3.29 | -3.85 | -3.58 | 2.44 | 0.58 | -0.69 | -3.07 | 2 | 49 | 49 | 6 | 1 | 1 | 0 | 0.00 | 0.49 | 0.49 | 0.00 | 0.38 | 0.00 | 0.00 | 0.00 |
5 rows × 191 columns
# model 생성
input_layer = Input((test[col].shape[1], 1))
output_layer = build_model(input_layer, 128)
model = Model(input_layer, output_layer)
# model 가중치 불러오기
model.load_weights('drive/Shared drives/빅콘테스트2020/weights/ds/functional_1.43-36.0185.hdf5')
# model2 = Model(input_layer, output_layer)
# model2.load_weights('')
# 주문량 예측
y_pred = model.predict(test[col].values)
real_test['판매단가'] = real_test['판매단가'].astype('int')
real_test['취급액'] = y_pred.reshape(-1) * real_test['판매단가']
real_test
| 방송일시 | 노출(분) | 마더코드 | 상품코드 | 상품명 | 상품군 | 판매단가 | 취급액 | 날짜 | 시 | 분 | 요일 | 휴일 | season | 노출횟수 | 판매단가등급 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2020-06-01 06:20:00 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | 59800 | 10715700.84 | 2020-06-01 | 6 | 20 | 1 | 0 | 1 | 1 | 1 |
| 2 | 2020-06-01 06:40:00 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | 59800 | 16863828.12 | 2020-06-01 | 6 | 40 | 1 | 0 | 1 | 2 | 1 |
| 3 | 2020-06-01 07:00:00 | 20 | 100650 | 201971 | 잭필드 남성 반팔셔츠 4종 | 의류 | 59800 | 28546873.53 | 2020-06-01 | 7 | 0 | 1 | 0 | 1 | 3 | 1 |
| 4 | 2020-06-01 07:20:00 | 20 | 100445 | 202278 | 쿠미투니카 쿨 레이시 란쥬쉐이퍼&팬티 | 속옷 | 69900 | 17404280.86 | 2020-06-01 | 7 | 20 | 1 | 0 | 1 | 1 | 1 |
| 5 | 2020-06-01 07:40:00 | 20 | 100445 | 202278 | 쿠미투니카 쿨 레이시 란쥬쉐이퍼&팬티 | 속옷 | 69900 | 29564540.76 | 2020-06-01 | 7 | 40 | 1 | 0 | 1 | 2 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2887 | 2020-07-01 00:20:00 | 20 | 100660 | 201989 | 쉴렉스 안마의자 렌탈서비스 | 무형 | 0 | 0.00 | 2020-07-01 | 0 | 20 | 3 | 0 | 1 | 1 | 1 |
| 2888 | 2020-07-01 00:40:00 | 20 | 100660 | 201989 | 쉴렉스 안마의자 렌탈서비스 | 무형 | 0 | 0.00 | 2020-07-01 | 0 | 40 | 3 | 0 | 1 | 2 | 1 |
| 2889 | 2020-07-01 01:00:00 | 20 | 100660 | 201989 | 쉴렉스 안마의자 렌탈서비스 | 무형 | 0 | 0.00 | 2020-07-01 | 1 | 0 | 3 | 0 | 1 | 3 | 1 |
| 2890 | 2020-07-01 01:20:00 | 20 | 100261 | 200875 | 아놀드파마 티셔츠레깅스세트 | 의류 | 69900 | 7021285.20 | 2020-07-01 | 1 | 20 | 3 | 0 | 1 | 1 | 1 |
| 2891 | 2020-07-01 01:40:00 | 16 | 100261 | 200875 | 아놀드파마 티셔츠레깅스세트 | 의류 | 69900 | 9228077.77 | 2020-07-01 | 1 | 40 | 3 | 0 | 1 | 2 | 1 |
2891 rows × 16 columns
real_test.to_csv("/content/drive/Shared drives/빅콘테스트2020/data/sample_submit", index=False)